文件同步是利用网络将多个电脑或移动设备之间的文件进行同步的网络服务。文件同步的本质是对比网络上两台设备之间的文件变更,然后将文件的不同部分通过网络进行传输,以达到文件同步的目的。本文介绍dropbox的文件同步实现原理。
基本概念
文件系统
在本地电脑上,一个文件可以用文件路径来标识。但对于dropbox需要支持共享目录,定义了名字空间(namespace)的概念,用于对传统文件系统的抽象。每一个共享目录有一个惟一的名字空间,每个用户有一个根名字空间,每个共享目录可以挂载(mount)到不同的用户根名字空间下。即对于dropbox的文件可以通过名字空间和相对路径<namespace,relative path>惟一标识。
文件格式
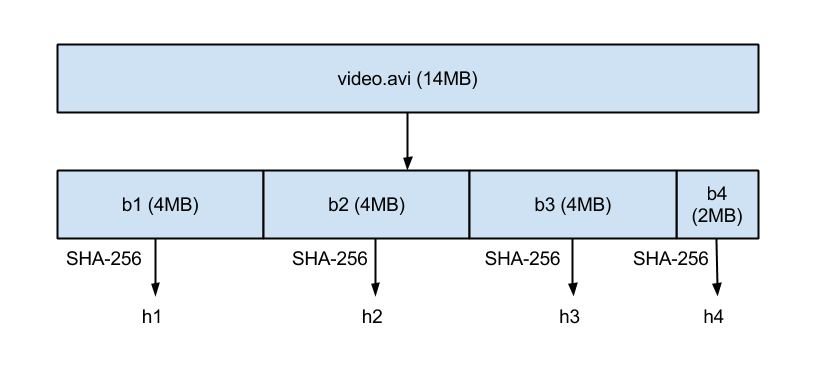
受rsync算法的启发,dropbox把每个文件被分割成4MB的块(最后一个块小于等于4MB)。每个块通过计算出的SHA-256进行标识,对于每个文件内容,可以通过一个块列表blocklist引用。比如,文件video.avi大小了14MB,可以分割成4个块h1, h2, h3, h4,我们说文件video.avi的块列表blocklist是[h1, h2, h3, h4],如下图:
服务器文件日志
服务器文件日志(The Server File Journal,SFJ)是一个大的文件元信息数据库,注意元信息中不包含文件内容,文件内容通过blocklist引用。服务器文件日志是一个不断追加的记录行,每一行代表文件的一个版本。每一行主要包含以下关键字段:
- 名字空间ID(Namespace ID,NSID)
- 名字空间下的相对路径(Namespace Relative Path)
- 块列表(Blocklist)
- 日志ID(Journal ID,JID),在名字空间下单调递增
Dropbox主要有两种服务类型:
块数据服务(block-server):维护一个key-value存储,key可以理解为每个块的hash值,数据是加密的。
元数据服务(meta-server):维护用户、名字空间、和SFJ数据库。
文件同步
dropbox的文件同步需要客户端和服务器共同完成。如果记本地文件集合为S1,上次已同步的文件集合为S2,服务器文件集合为S3。通过对比S1、S2,可以找出本地文件变更;通过对比S2、S3,可以找出服务器端文件变更。找到文件变更后,客户端需要与服务器进行上传、下载操作,以完成文件同步。
这里不讨论如何找出文件变更的实现方式,后面会针对这个主题单独写一篇。这里主要讨论dropbox客户端和服务器上传下载的交互流程。
上传
文件变更后,如果重新上传整个文件,无疑会极大增加网络数据传输以及同步效率。上文提到dropbox是将数据按4MB进行分块,且元数据和数据分离,客户端跟服务器交互时主要分成了三个步骤:
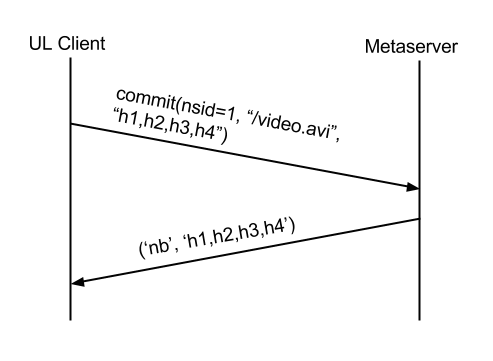
第一步客户端是跟meta-server交互,尝试将文件提交commit至指定的名字空间的路径下<nsid,path>。服务器需要检查:
- 用户是否有权限访问这个名字空间
- 文件的块列表是否存在
成功后,服务器返回需要上传的块列表,交互流程如下:
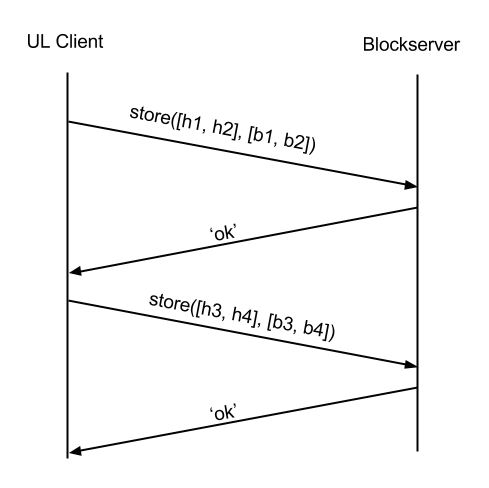
第二步是客户端跟data-server交互,上传第一步中服务器返回的需要上传的块列表数据,可以进行批量上传。流程如下:
第三步其实跟第一步一样,再次将文件提交至指定名字空间的路径下,但这次必定会成功,因为所有文件块已经存在了。如果对于一个已经上传过的文件,由于之前这个文件已经上传过,所以第一步就会成功,这便是我们所说的“秒传”。
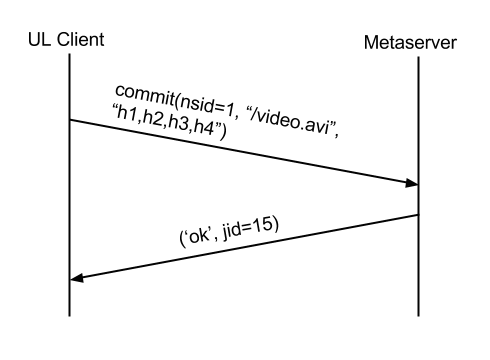
经过上面三个步骤(秒传只需要一步),用户的文件就已经存储到了dropbox中。
下载
下载是要将服务器侧的文件变更同步至本地,主要包括两个步骤,第一步是将服务器侧的文件meta变更同步至本地,第二步是将文件的数据下载至本地,在本地重新构造出变更后的文件。
客户端首先跟meta-server交互,通过指定名字空间和该名字空间下的cursor,发起一个list调用以增量获取指定名字空间下的文件变更。每次获取到文件变更后,服务器同时还会返回一个新的cursor,客户端会缓存这个cursor以便下次调用时使用,具体流程如下:

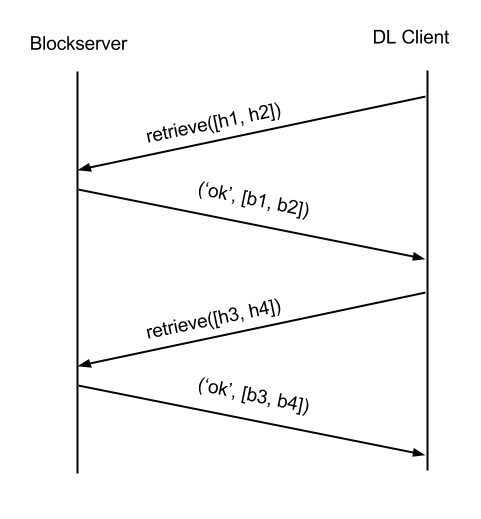
拿到变更后的文件元信息后,需要通过块列表blocklist重新构造文件数据。客户端首先检查这些块是否在本地已缓存,如果未找到,客户端会向block-server发起一个retrieve调用,下载具体块的数据,retrieve操作支持批量。当所有块都下载到本地后,客户端重新构造文件,并将其将添加到本地文件系统中。流程如下:
一些思考
云盘属于个人云存储赛道,其核心竞争力在于存储成本、带宽成本、数据安全性以及用户基数(数据迁移成本高)。目前国内云盘C端市场竞争激烈,很难在沿用现有模式下有所突破,可以针对细分人群或场景下做差异化以寻找生存空间。