写在前面
之前写过一篇Go并发编程模式,相对比较片面。最近系统看了下Concurrency in Go, 结合自身的一些实践,形成本文,算是一个读书笔记吧。
为什么需要并发
Concurrency is the next major revolution in how we write software.
—— The Free Lunch Is Over
摘自 Herb Sutter 2005年在Dr. Dobb’s 发表的文章:The Free Lunch Is Over。核心思想是说摩尔定律逐渐失效,但数据规模却在不断增长,我们需要充分挖掘多核计算机性能,而并发编程是编写软件方式的重大革命。
那什么是并发呢?并发跟并行有什么区别?
并发与并行
并发(concurrency)和并行(parallelism)有相关性但却是截然不同的概念。Rob Pike在Concurrency is not parallelism主题演讲中总结的非常好:
Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
—— Concurrency is not parallelism
并发是指同时处理(dealing with)多件事,并行是指同时去做(doing)多件事;并发强调在逻辑上(logically)同时发生;并行强调在物理上(physically)同时发生。
举个例子:单核CPU是可以并发的,但不能并行;多核CPU即可以并发,也可以并行。
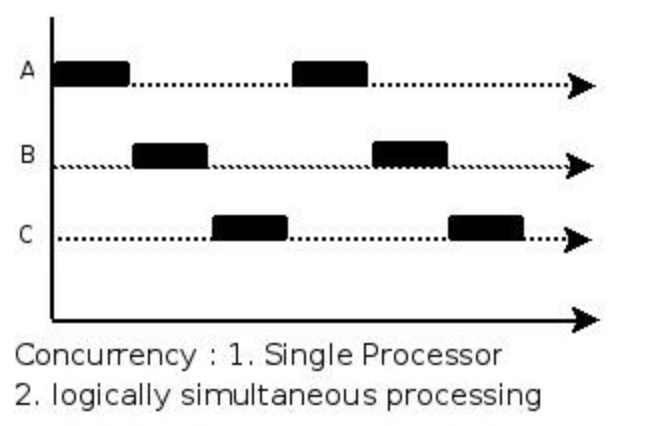

但是,编写正确的并发程序是困难的!
并发编程的困难性
程序员已经习惯于代码是按照顺序执行的,这也符合我们的思维习惯。但并发执行顺序是不确定的,这种不确定性带了很多问题,先来看个简单的示例:
1 | var data int |
上面示例中,由于并发执行的不确定性,有三种结果:
- 不输出任何结果
- 输出 “the value is 0”
- 输出 “the value is 1”
具体来讲,并发主要面临以下问题:
- 竞争条件(Race Conditions)
- 原子性(Atomicity)
- 内存访问同步(Memory Access Synchronization)
- 死锁、活锁和饿死(Deadlocks、Livelocks and Starvation)
- 并发安全性(Determining Concurrency Safety)
基础知识
通信顺序进程CSP
Communicating Sequential Process,通信顺序进程是一种并发编程模型,可以说是复兴的古董,最早是C. A. R. Hoare在1978年在论文 Communicating Sequential Processes 提出。
CSP模型也是由独立的、并发执行体组成,实体之间是通过发送消息进行通信。CSP模型不关注发送消息的实体,而是关注发送消息时使用的通道(channel)。这便是我们在Go中进行并发编程时首先要转变的观念:
Do not communicate by sharing memory; instead, share memory by communicating.
—— Share Memory By Communicating
不要通过共享内存进行通信;相反,使用通信(channel)来共享内存。
需要注意的是,上述信条是在Go社区中倡导的,但并意味着所有并发编程都应该使用CSP,CSP是否适用还是要看具体使用场景。
Go语言对并发的支持
在Go中,并发(goroutine)和通道(channel)变成了一等公民,使用go启动一个协程,使用channel在协程之间通信,使用select对多通道进行操作。
goroutine
A goroutine is a function executing concurrently with other goroutines in the same address space.
—— Effective Go
不同于操作系统的线程,goroutine是在用户态实现的,多个goroutine间共享同一地址空间。它具有轻量级、开销小、需要的栈空间小等特点(但这并不意味可以它是免费的)。
在Go中,启动一个goroutine十分简单:
1 | go list.Sort() // run list.Sort concurrently; don't wait for it. |
channel
A channel provides a mechanism for concurrently executing functions to communicate by sending and receiving values of a specified element type.
channel是Go语言层面提供的一种数据结构,用于gouroutine之间通信。从channel类型来看可以分为:
- 无缓冲区channel(unbuffered channel):c := make(chan T)
- 有缓冲区channel(buffered channel):c := make(chan T, cap)
从数据流向来看,分为:
- 双端channel:支持读和写操作
- 只读channel(receive only channel):←chan T
- 只写channel(send only channel):chan← T
以下是在给定channel状态后,对其进行read、write和close操作的结果:
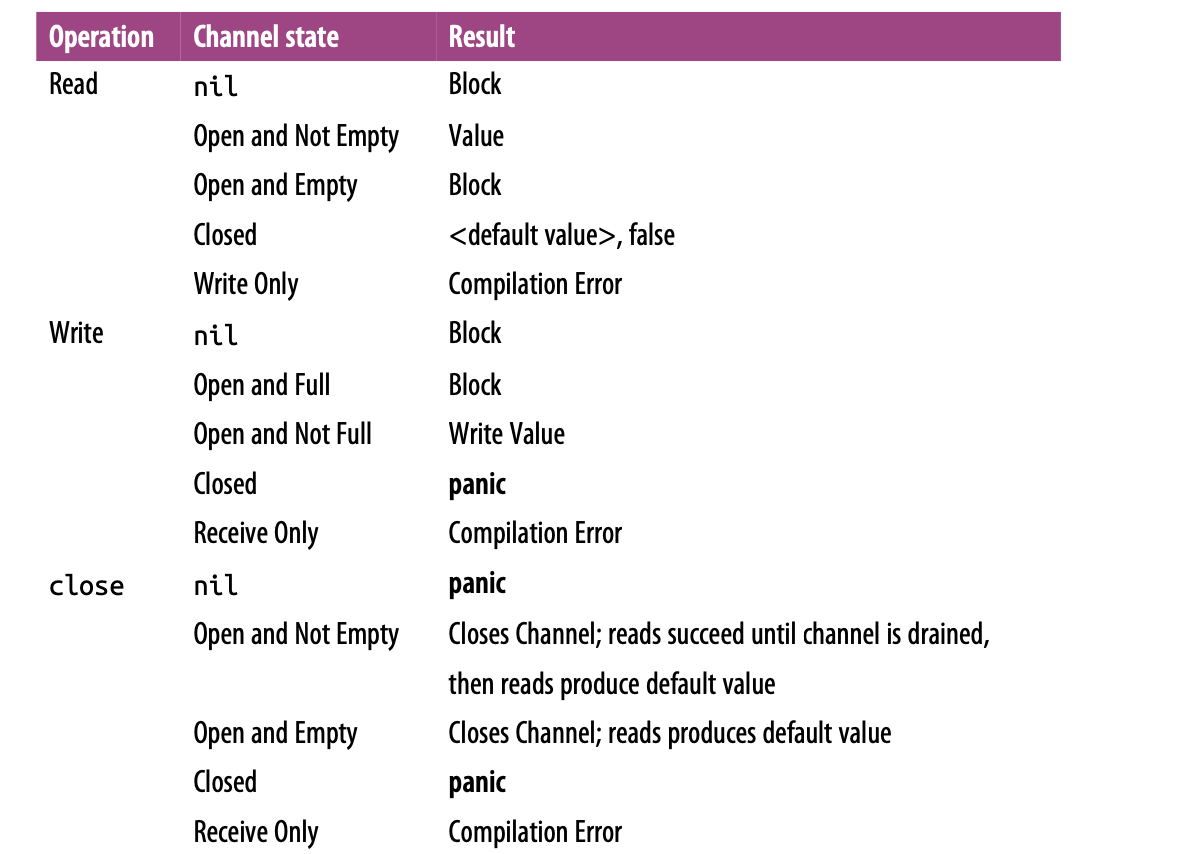
注意上表中几个panic:
- 向已经关闭的channel中写数据会panic
- 关闭状态为nil的channel会panic
- 关闭已经关闭的channel会panic
更多关于 channel 的使用参考:Language Specification Select statements.
select
在类C的语言中,控制结构通常包括:if,for,while,switch,break,continue;在Go中,提供了一种全新的控制结构 select 用于对多通道操作的控制。
1 | select { |
更多关于 select 使用参考:Language Specification Select statements.
Go标准库对并发的支持
Go并发编程模式
两个原则
Rethinking classical concurrency pattern 从传统并发编程模式角度出发,总结了两个条Go并发编程的原则:
- Start goroutines when you have concurrent work
- Share by communicating
第一条原则是指:如果需要对所做的工作进行并发,那首先需要将工作拆分成可发并的单元。
第二条原则是指:并发之间的通信通过消息传递,而不是共享内存。
对于第二条原则还是要根据实际情况来判断,Go语言提供了比较高级的并发编程工具(go、channel、select),以下总结了一些并发编程模式可供参考和借鉴。
限定作用域
限定作用域并不是一个新鲜的概念,在面向对象(OO)中的封装,函数式编程中的闭包(Closure)都可以理解为限定作用域,其本质是通过语法层面对数据的作用域加以限制,使其更容易被理解,并减少或消除被误用的条件。
在限定作用域的例子中,做了以下限制:
- 将创建、写入、和关闭都限定在chanOwner的作用域中,并返回一个receive only的channel
- 在consumer中对receive only进行只读操作,并等待channel关闭。
通过限定作用域,实际上是对功能的约束,可以更明确的表明channel的作用范围,规避一些不正确的用法。
For-Select Loop
在Go中,for-loop是一种惯用法,模式如下:
1 | for { // Either loop infinitely or range over something |
通常有以下场景运用:
将迭代器中的值发送到一个channel中:
1 | for _, s := range []string{"a", "b", "c"} { |
从一个channel中读取数据处理后写入到另一个channel中:
1 | for s := range in { |
无限循环并等待退出:
1 | for { |
注意,以上每种for-loop的变种,select都加了一个←done操作,是为了防止出现死循环导致goroutine泄露的情况。后面会讨论用更通用的context包解决这个问题。接下来将讨论一些关于如何避免goroutine泄露的模式。
防止goroutine泄露
对于一个goroutine,通过有以下三种路径结束其生命周期:
- goroutine完成任务自动退出
- goroutine在执行过程中遇到不可恢复的错误而不能继续后续任务
- 调用端取消goroutine
防止goroutine泄露的一条经验法则是:
If a goroutine is responsible for creating a goroutine, it is also responsible for ensuring it can stop the goroutine.
—— Concurrency in Go
解铃还须系铃人,谁负责创建一个goroutine,也有责任对它的整个生命周期负责。
- 可能发生goroutine泄露的例子:https://go.dev/play/p/bAx4c6CXm7V
- 防止goroutine泄露:https://go.dev/play/p/ZfELCscQCzl
在这个例子中,main在调用doWork启动一个goroutine后,同时指定了一个done channel,用于超时控制,如果goroutine超过1s未返回,关闭done channel让goroutine退出。也就是说创建goroutine的协程一定要保证被创建的协程能够退出。
后面讲到context时,会采用更通用的方式实现。
Pipeline
Go Concurrency Patterns: Pipelines and cancellation 中关于pipeline在Go中的定义:
a pipeline is a series of stages connected by channels, where each stage is a group of goroutines running the same function.
—— Go Concurrency Patterns: Pipelines and cancellation
pipline是由一系列通过channel连接的阶段组成,对于每个阶段(stage),goroutines主要包括以下三个部分:
- 通过inbound channels从上游接受数据
- 处理数据
- 将处理后的数据通过outbound channels发送给下游
除了第一个阶段和最一个阶段外,每个阶段都可以有一个或多个inbound channel和一或多个outbound channel。第一个阶段通常叫源(source)或生产者(producer),最后一个阶段通常叫槽(sink)或消费者(consumer)。
一个包含3个阶段的pipeline的例子:https://go.dev/play/p/D_iBejB3hgW
在这个例子中,原始数据[1, 2, 3]经过每个阶段(gen、add、sq)进行处理,阶段与阶段之间通过channel进行连接,最后可以读取pipeline channel输出结果。
数据通过channel很优雅在每个阶段之间流动,但如果某个阶段处理特别慢的情况下,下游阶段就需要等待上游处理完才能拿到数据。那如何提供各个阶段处理数据的效率呢?
根据pipleline的定义,如果数据之间没有依赖关系的话,每个阶段可以包含一系列goroutine并发地处理。这便引出Go的另一种并发编程模式—— Fan-out, Fan-in。
注意使用 Fan-out, Fan-in 模式的前提是:
- 阶段处理数据效率影响整体性能
- 数据之间没有依赖
Fan-out, Fan-in
根据 Concurrency in Go 中关于Fan-out, Fan-in的定义:
Fan-out is a term to describe the process of starting multiple goroutines to handle input(same input) from the pipeline.
Fan-in is a term to describe the process of combining multiple results into one channel.
—— Concurrency in Go
扇出(Fan-out):是指启动多个goroutine处理来自同一个输入的过程。
扇入(Fan-in):是指将多个输出结果合并到一个通道的过程。
如下图所示:
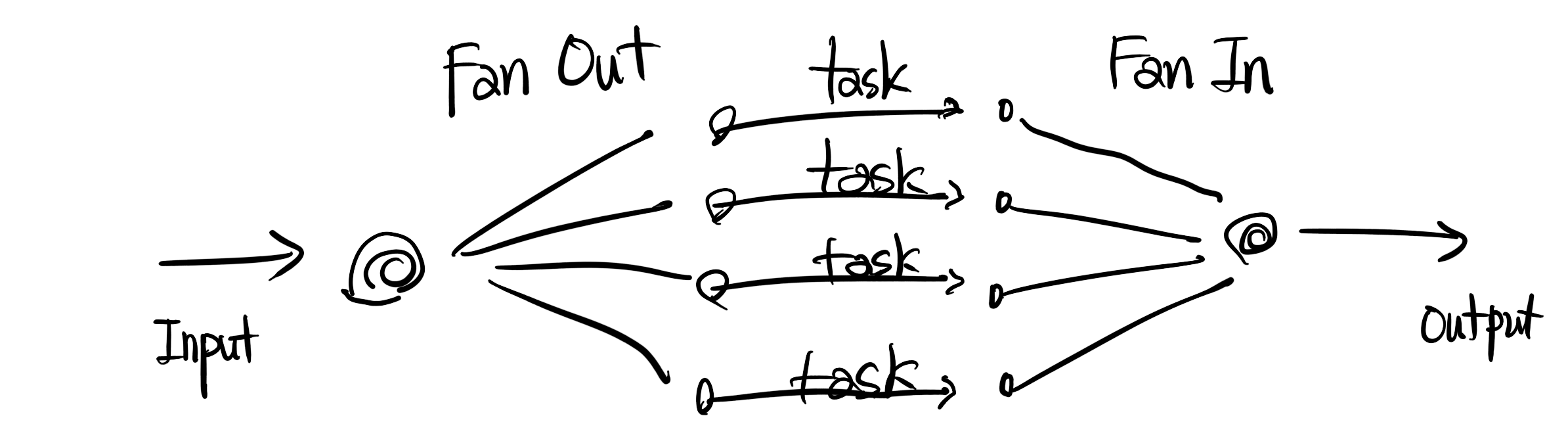
以下是Fan-out,Fan-in的两个示例:
- Fan-out的例子:https://go.dev/play/p/is4YFOJcuIu
- Fan-in的例子:https://go.dev/play/p/8rxF_KPZPO6
在上述例子中,如果没有,如果某个阶段如现错误,或者想在中途停止pipeline,该如何实现呢?
标准库context已经为我们提供了优雅退出协程的接口。
Context
Go标准库提供了context包用于处理超时、取消、API边界的上下文数据传递。
package context defines the Context type, which carries deadlines, cancellation signals, and other request-scoped values across API boundaries and between processes.
接口定义也比较简洁:
1 | type Context interface { |
标准库context有对接口的完整说明以及example,在此不展开。另外还有一篇关于context非常好的文章:Go Concurrency Patterns: Context
关于context的一个惯用法是:
Contexts should not be stored inside a struct type, but instead passed to each function that needs it.
至于为什么要这么做,在文章 Contexts and structs 中有非常详细的理由解释。最主要的原因是:
- 接口维度进行deadline、cancellation以及metadata传递控制;
- 更容易理解,作用域更清晰;
- 在跨库或跨API调用上可以在调用堆栈中暴露context信息,更容易调试;
再回头看pipleline的例子,可以通过在每个阶段传递一个context参数,以进行deadline、cancellation以及request-scoped values控制。
使用context优雅退出的pipeline例子:https://go.dev/play/p/q7u1w60LPNv
一个完整的例子
很多类Unix操作系统中都自带了一个实用的工具md5sum,但这个工具不能对文件夹进行递归处理。在这个例子中,我们会完善这个工具。为了展示对Go并发编程的实际应用,这个例子将从一个串行的实现开始,然后再展示如何转换为并发实现,最后为了让工具更实用,还会展示如何接收系统信号实现协程的优雅退出。
- 串行实现:md5sum-sequential.go
- 并发实现:md5sum-concurrency.go
- 并发优雅退出实现:md5sum-context.go
实践
在工程实践中,如果数据量比较大,数据通常会进行分片存储。如果有数据聚合需求,且这些分片之间的数据没有顺序依赖,对各个分片的数据获取就是一个独立的并发单元。此时我们可以并发地从各个数据分片中获取数据以提高数据的处理效率。框架代码如下:
1 | func FetchData(ctx context.Context, ids []string) ([]*DataNode, error) { |
总结
- 我们首先介绍了为什么需要并发以及并发编程的困难性,然后介绍了Go语言对并发编程的支持以及基本构造块。
- 接着介绍了在Go语言中常用的并发编程模式,再通过一个实用的例子md5sum来加深对这些模式的理解。
- 最后介绍如何将这些模式应用到多分片的数据聚合实际工作场景中。
参考资料
- Concurrency in Go
- Concurrency is not parallelism
- Share Memory By Communicating
- Go Concurrency Patterns
- Advanced Go Concurrency Patterns
- Rethinking classical concurrency pattern
- Effective Go
- go-concurrency-patterns all in one
- Go Concurrency Patterns: Pipelines and cancellation
- Go Concurrency Patterns: Timing out, moving on
- Go Concurrency Patterns: Context
- Contexts and structs