写在前面
MySQL是一款开源的关系型数据库,广泛应用于Web后端的数据存储。索引是MySQL非常重要技术组成部分,深入理解MySQL的索引原理,有助于我们建立高性能的索引以及对索引进行调优。
MySQL支持多种索引类型,如B-Tree索引、哈希索引、全文索引等。索引是在存储引擎中实现的,在实际环境中,应用比较多的是InnoDB存储引擎和MyISAM存储引擎,这两个存储引擎底层都是使用的B-Tree索引。所以,为了不引起歧义,本文讨论的MySQL索引,没有特殊说明,都是指的B-Tree索引。
什么是索引
当你想在一个图书图找到一本书时,比如《高性能MySQL》,你会怎么做呢?
首先你通过一级分类找到计算机类的书籍摆放的位置,然后通过二级分类找到数据库相关的书籍的摆放位置,最后通过书名的字母顺序找到这本书。
这里的分类就是索引,简单来说,索引能够帮忙我们快速找到需要的数据。MySQL中的索引的工作原理跟这个例子类似,MySQL对索引的定义是:
索引是存储引擎用于快速查找记录的一种数据结构。
B-Tree索引
B-Tree索引是一种索引类型,并不是说它的实现就是使用B-Tree数据结构,实际上,B-Tree索引使用的是B+Tree实现。B-Tree是种自平衡树,其节点中的数据都是排好序的。
对于非叶子页节点,包含N-1个键和N个指向下一级页结点的指针。对于叶子页节点,包含了排好序的值,B+Tree跟B-Tree的最大区别是在叶子页节点中,每个页节点还存储了指向下一个页节点的指针。如下图所示:
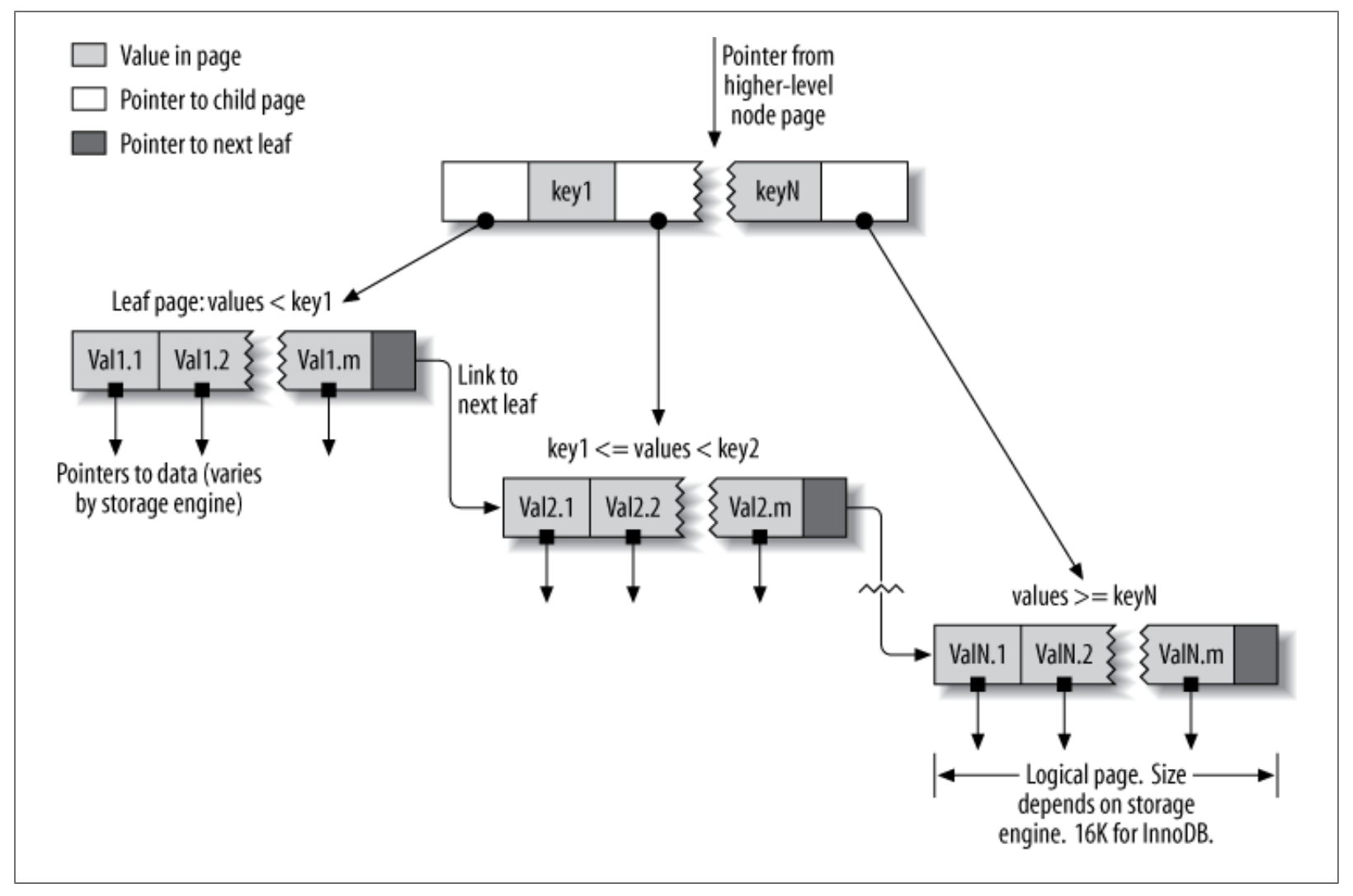
在MySQL中,B-Tree索引中的每个节点的内容实际上是存储在一个页(Page)中,默认情况下,页的大小是16KB。之所以采用页为单位存储,是因为读磁盘需要进行IO操作,而磁盘IO操作通常比较耗时,一次加载一页的内容,主要是为了减少跟磁盘的IO次数。
所以在一页中查找目标数据时,都是在内存中进行的,由于一个页节点中的数据都是排好序的,所以采用二分查找,仅需要O(log2N)的时间复杂度就可以完成检索。
聚簇索引与非聚簇索引
聚簇索引(clustered index)并不是一种单独的索引类型,而是一种数据存储方法。聚簇的意思是索引跟数据行是保存在一起的。而非聚簇索引是相对于聚簇索引而言的,就是索引和数据是单独存储的。
MyISAM存储引擎采用非聚簇索引存储数据,而InnoDB存储引擎采用聚簇索引存储数据。来看下MyISAM和InnoDB是如何存储下面的表:
1 | CREATE TABLE layout_test ( |
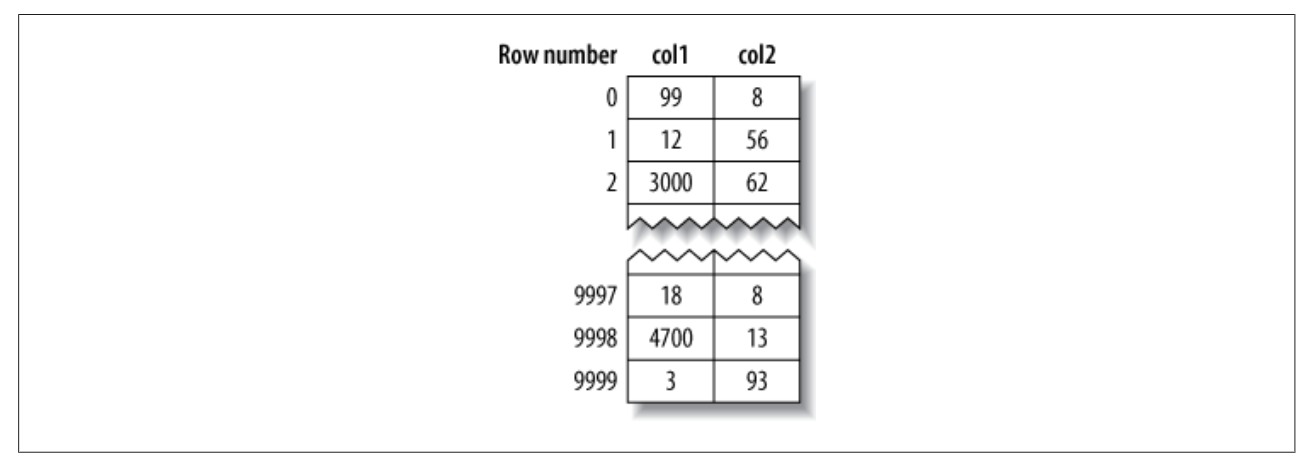
对于MyISAM,其数据分布比较简单,按照数据插入的顺序存储在磁盘上。对于每一行数据,都是一个行号,从0开始递增。由于行是定长的,所以MyISAM可以从表的开头跳过所需的字节找到需要的行(有点类似于数组)。如下图:
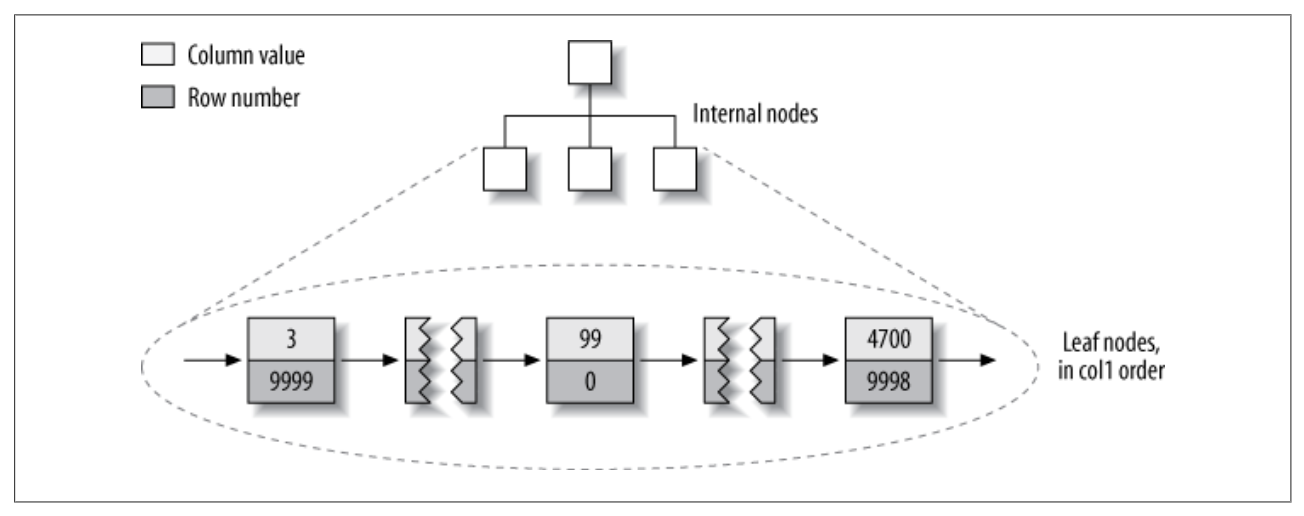
MyISAM使用主键索引查找数据时,在B+Tree的叶子节点除了存储索引键之外,还保存了每个键所处的行指针(可以理解为行号)。当找到某个索引键对应的行指针后,就能定位到它对应的数据。如下图:
对于MyISAM的二级索引,它的存储方式跟主键索引没有什么区别,如下图:
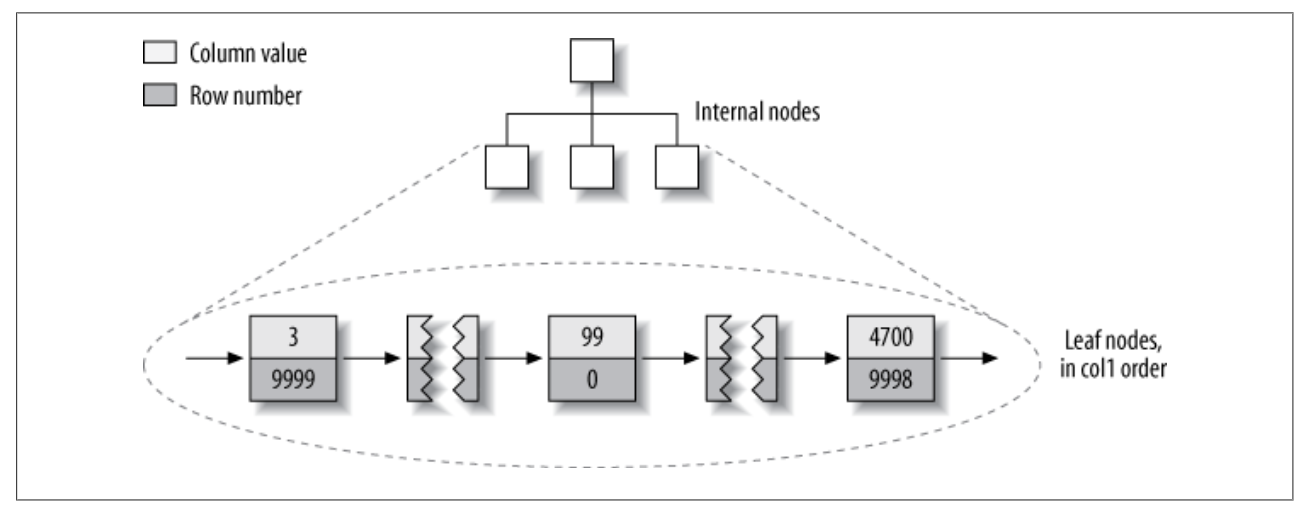
所以对于MyISAM来讲,主键索引和其它索引在存储结构上并没有什么区别。主键索引就是一个名为PRIMARY的惟一非空索引。
对于InnoDB来讲,主键索引是聚簇的,也就是主键索引就是表,所以不像MyISAM那样需要独立的行存储。 聚簇索引的每个叶子节点都包含了主键值、事务ID、用于事务和MVCC的回滚指针以及所有剩余列(这个例子中是col2)。对于InnoDB的主键索引,数据分布如下图:
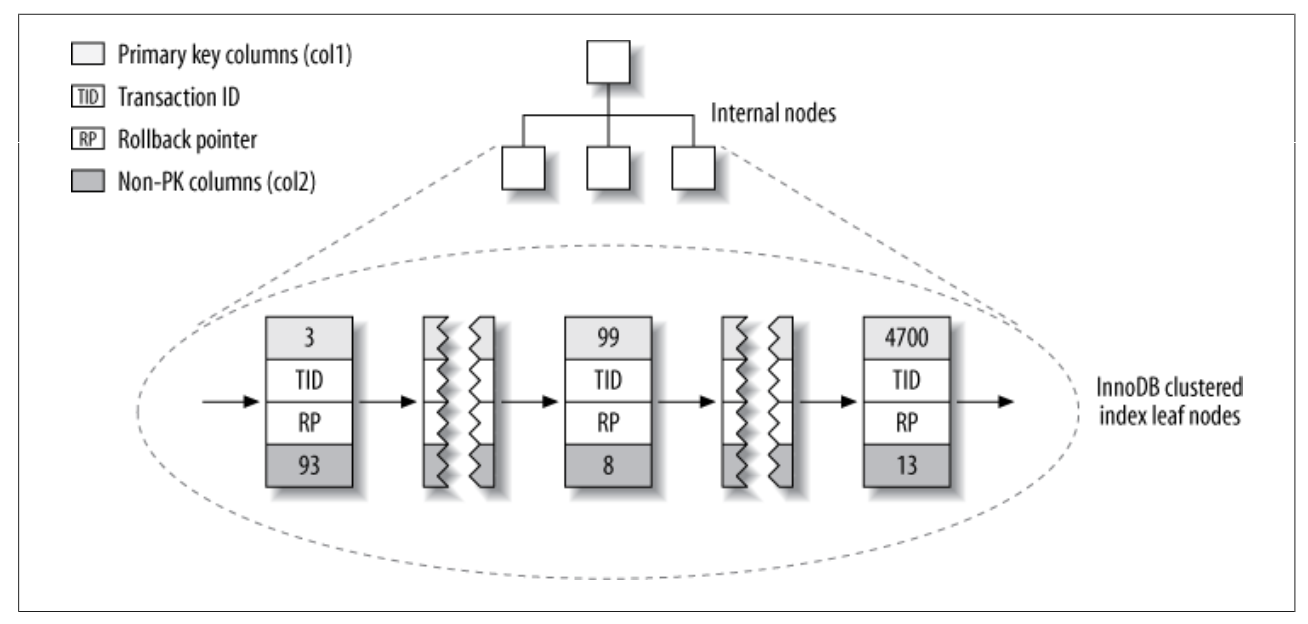
InnoDB的二级索引和聚簇索引区别比较大,它的二级索引的叶子节点存储的不是”行指针”,而是主键值。存储主键值带来的好处是,InnoDB在移动行时无须更新二级索引的这个指针。如下图:
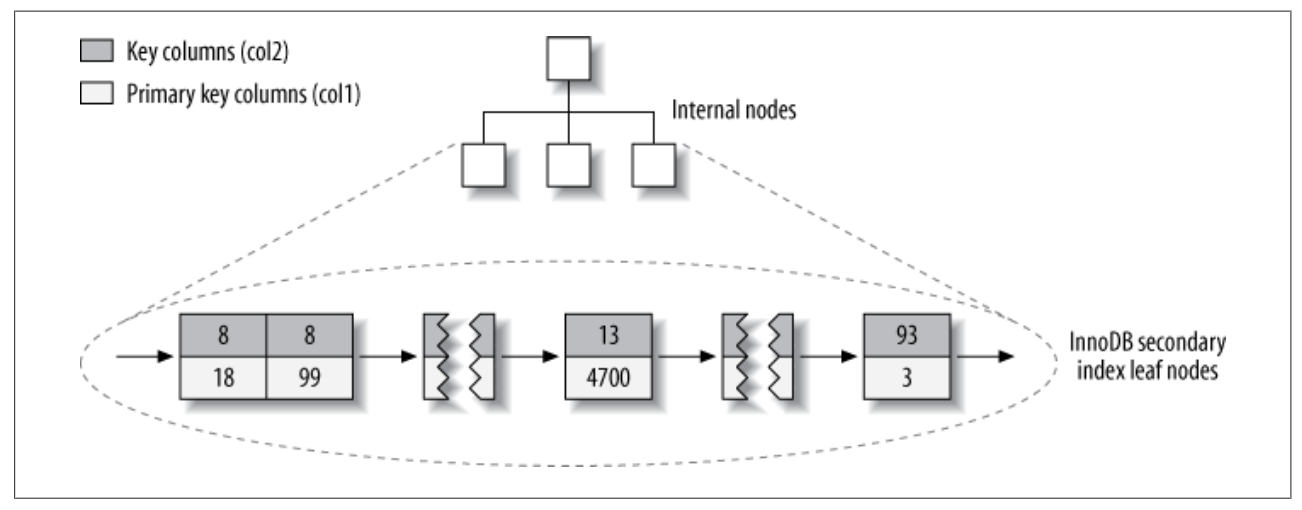
由于InnoDB是通过主键聚集数据,所以使用InnoDB时,一定要指定主键,如果没有定义主键,InnoDB会选择一个惟一的非空索引代替,如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。
由于聚簇索引插入速度严重依赖于插入顺序。按照主键的顺序插入是加载数据到InnoDB表中速度最快的方式,所以通常我们都使用一个递增ID作为主键。
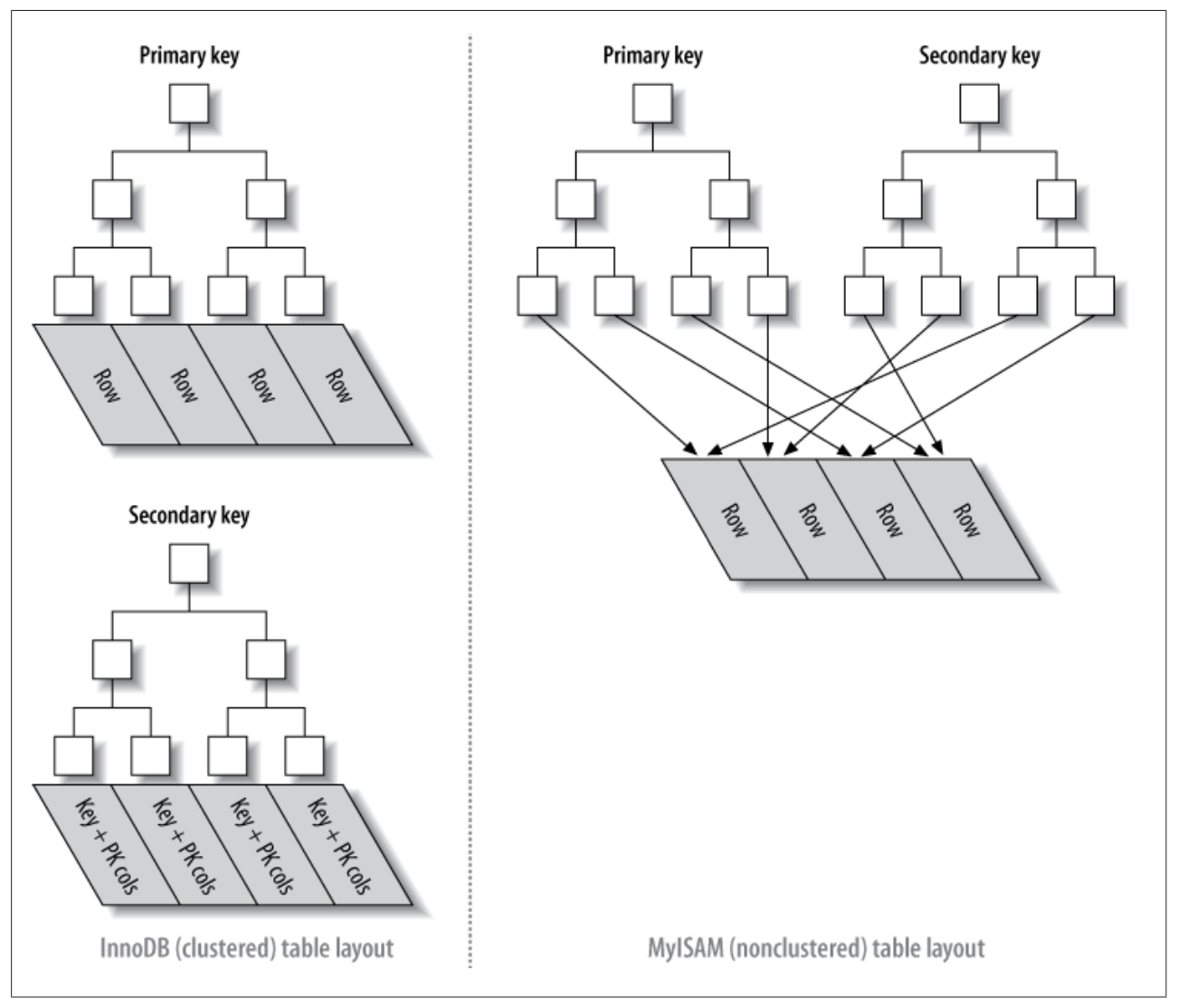
最后,我们使用一个比较抽象的图,对比一下聚簇和非聚簇的数据分布:
联合索引与最左前缀原则
联合索引也叫多列索引。索引是可以包含一个或多个列值的。对于InnoDB,最多可以指定16个列,见InnoDB Limit。比如下面数据表:
1 | CREATE TABLE People ( |
对于索引idx_lfd,索引中包含了last_name、first_name和dob列的值,下图展示了B+Tree的存储结构:
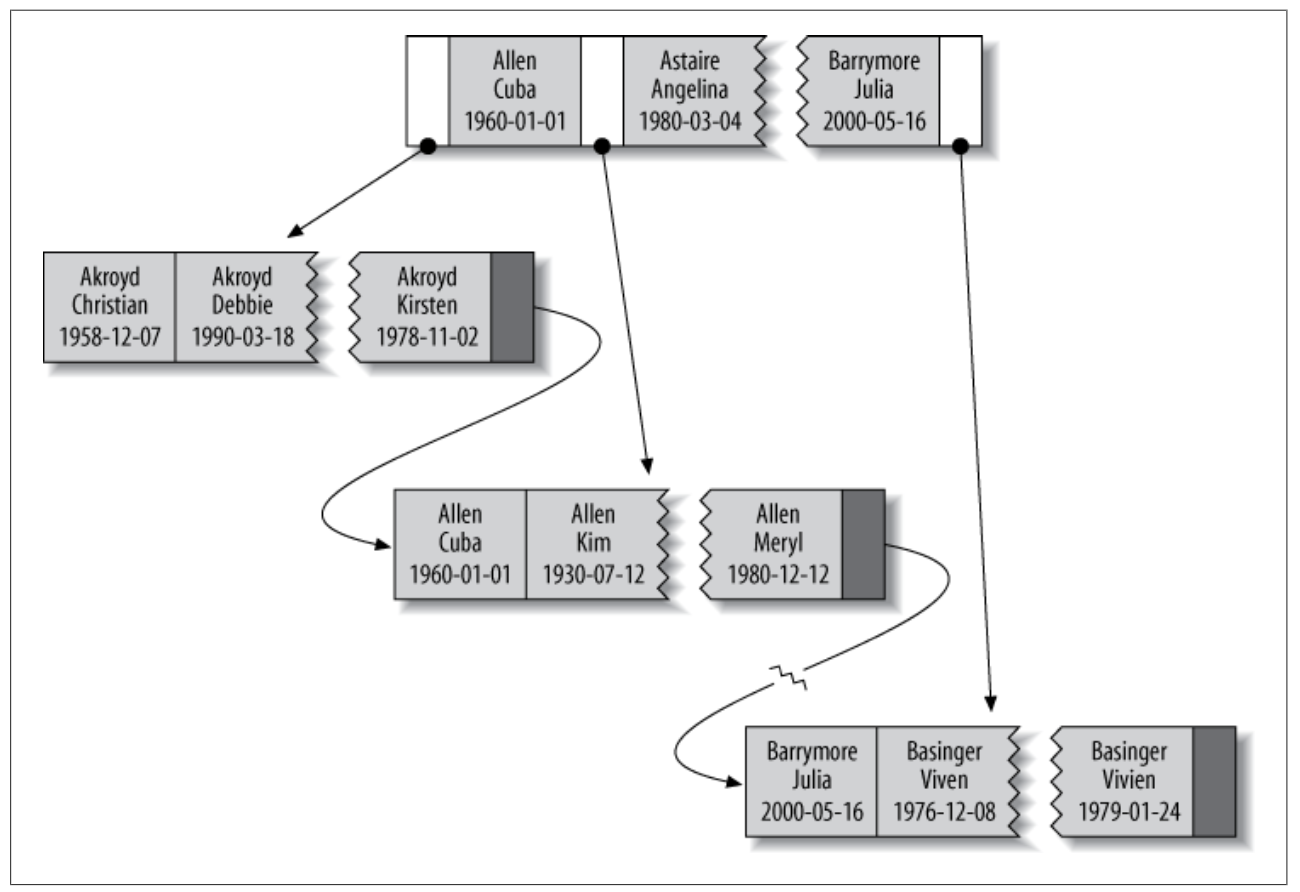
当索引包含多列时,其排序方式跟建立索引时指定的列顺序有关。
比如对于索引idx_lfd,排序时,先根据last_name排序,如果last_name相同,再按照first_name排序,如果first_name也相同,再按dob排序。再看上图的节点中的 {Basinger, Viven, 1976-12-08} 和 {Basinger, Viven, 1979-01-24},first_name和last_name都相同,所以按dob排序后,{Basinger, Viven, 1976-12-08} 在 {Basinger, Viven, 1979-01-24} 前面。
根据联合索引的特点。B-Tree索引除了支持全键值和键值范围外,还支持键前缀查找。其中键前缀查找只适用于最左前缀原则。其中包括:
- 全值匹配:指和索引中的所有列进行匹配。例如查询姓名为Cuba Allen,出生于1960-01-01的人。
- 匹配最左前缀:只使用索引的前缀列,例如上面例子中查找所有姓为Allen的人。
- 匹配列前缀:匹配某一列的开头部分。例如查找所有以J开头的姓的人。
- 匹配范围值:查询某一列的范围。例如查找姓在Allen和Barrymore之间的人。
- 精确匹配某一列并范围匹配另外一列:全匹配第一列,范围匹配第二列。例如查找所有姓为Allen,名字以字母K开头的人。
- 只访问索引的查询:只查询索引覆盖的列,无须访问数据行,也就是我们说的覆盖索引。
索引优化策略
了解了索引的实现原理后,索引的优化相对比较简单些。这里的简单是指优化的套路比较简单,只要你熟悉最左前缀原则以及知道索引的选择性,具体实施是比较简单的。
索引的选择性是指,不重复的索引值(也称为基数,cardinality)和数据表记录总数(#T)的比值,范围从1/#T到1之间。索引的选择性越高查询效率越高。因为选择性高的索引可以让MySQL在查找时过滤掉更多的行,惟一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
也就是说,我们在创建索引时,应该在满足业务查询需求的前提下,尽可能地提高索引的选择性。这便是索引优化的艺术。