上一篇 Lab2: 概述 中简要介绍了Raft,本篇介绍Raft选主的原理和实现。实验二共包含四个子实验:
本文是第一个子实验,需要实现Raft选主。Raft具有强领导人特性,也就是说Raft需要先选举出领导人后才能进行后续操作。在开始实验前,先阅读以下材料:
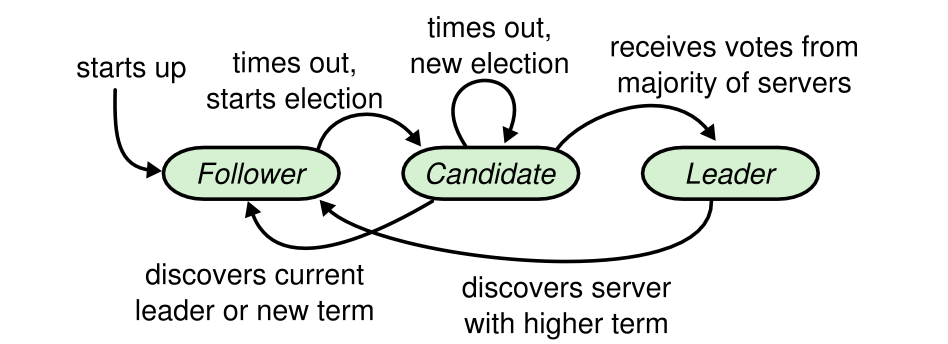
基本原理 Raft有三种角色:领导人(leader)、候选人(candidate)和追随者(follower),每个Raft节点都可能是这三种状态中的一种,但大部情况下,集群中只有leader和follower两种角色的节点。三种角色的转换关系如下图:
节点启动时设置为follower状态,处于follower状态的节点如果在选举超时时间内没有收到leader的心跳消息将转换为candidate状态,candidate状态的结点会发起投票,首先会给自己投票,然后全网广播,让其它节点给自己投票,如果candidate节点收到了半数以上(majority)的投票,节点转换成leader状态。成为leader状态的节点会定时向全网发送心跳,以表示leader健在,让其它节点都安份点,别挑战leader的权威。集群中的candidate节点在收到leader的心跳后,转换为follower状态。
以上的节点的状态转移可以形象理解为,每个follower都有一颗不安分的心,如果在一段时间内(选举超时时间)没有收到leader的心跳消息,就跳出来参加竞选,让群集中的其它节点都选举它当leader,如果超时半数的节点都同意,那它就成为leader了。同样,为了不让其它节点再把自己推翻,它要不断地向群集广播心跳以维护自己的leader地位。
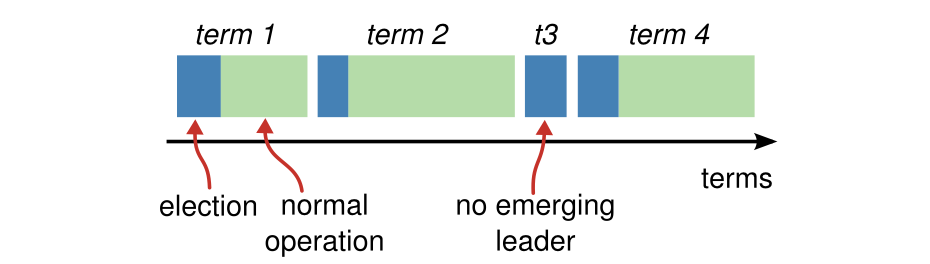
每次选举都有一个任期(Term),标识惟一的一次选举。一个candidate发起选举时,会出现三种情况:
1、赢得选举,成为leader。
前两种情况都比较容易理解,第3种情况发生在集群中有多个候选者时,候选者获得的选票均没有过半,相当于这个任期(Term)没有选举出领导人。任期相当于一个递增的时钟向量(Clock Vector),如果放在时间维度,每个任期包含选举周期和任期内的操作,其中任期内的操作是可选的,这种情况相当于这个任期没有选举出领导人,下图可以直观看出时间维度任期的变化过程:
上图中,正常情况下,每个任期(Term)都包含一个选举周期和任期内的普通操作,但任期3(Term=3)发生投票分裂,没有选举出领导人,任期4发生重新选举,选举出新领导人后,进行后续操作。
实现 以上基本原理中介绍了选举的过程,是不是感觉还是挺容易理解的。但从实现角度,我们需要一种更精确的语言来描述整个选举过程,论文作者给出了两个RPC用于实现选主,分别是:
RequestVote RPC:canidate向其它节点发起投票。
AppendEntries RPC:leader向其它节点发起心跳或日志复制,在本文中我们只需要关注心跳部分。
这两个RPC的实现在论文中Figure 2中有详细描述,下面会提到。如果一开始就从这两个RPC入手,其实是比较难理解为什么这两个RPC就能够完成选主。我们需要先了解Raft有哪些状态(Figure 2中左上图),由于Raft中的部分状态是跟Raft的角色是有关系的,RPC操作也是在某种角色下进行的,所以理解了这些状态后,我们还需要理解Raft的角色转换,在这两个基础上再理解这两个RPC就容易了。
Raft状态 在Figure 2中的State部分,包含了一个Raft应该具有的状态,可以从两个维度去理解,第一个维度是是否需要持久化;第二个维度是状态适用的角色。这两个维度在论文Figure 2中已经明确给出。这个图在后续实验中也会反复回顾,建议多看几遍,务必理解其中的每一个状态。但在实验2A中,我们只需要关注以下状态:
currentTerm:当前任期号,需要持久化,适用于任何角色。
votedFor:当前任期中,投票给了谁。需要持久化,适用于任何角色。
除此之前,我们还需要一个角色状态state来记录当前Raft节点所处的角色,state枚举值为:
Follower:追随者
Candidate:候选者
Leader:领导人
Stopped:已退出,用于退出控制
角色状态转移 角色状态转换过程中涉及到两个定时器,一个时选举超时定时器,另一个是心跳定时器。选举超时定时器是follower角色在指定时间内没有收到leader的心跳消息自动转换为candidate参加竞选;而心跳定时器是leader为了维护自己的领导地位,定时向群集广播自己还存活着,让follower都好好干活,不要造反。
按照论文作者给的建议,两个定时器设置为:
1 2 3 4 const ( DefaultHeartbeatInterval = 50 * time.Millisecond DefaultElectionTimeout = 250 * time.Millisecond )
我采用事件驱动的方式,将Raft所有的操作都放到事件循环中处理,而事件循环则放在一个单的线程中进行(one loop per thread)。Raft启动时,角色状态设置为follower,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func (r *Raft) startLoop () r.setState(Follower) r.wg.Add(1 ) go func () defer r.wg.Done() r.loop() }() } func (r *Raft) loop () state := r.State() for state != Stopped { switch state { case Follower: r.followerLoop() case Candidate: r.candidateLoop() case Leader: r.leaderLoop() default : Warning("raft.loop: server[%v] running unknown state[%v] at term[%v]" , r.me, state, r.CurrentTerm()) } state = r.State() } }
Follower循环 处于follower角色的节点,可以接收AppendEntries RPC请求,也可能会收到候选者的RequestVote RPC请求。同时,如果选举超时时间内没有收到leader的心跳,则转换为candidate。需要注意的是,为了防止投票出现分裂的情况,选举超时采用随机算法,随机时间我选择为[选举超时, 2*选举超时],如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 func (r *Raft) followerLoop () timeoutC := afterBetween(DefaultElectionTimeout, 2 *DefaultElectionTimeout) for r.State() == Follower { var update bool select { case <-r.stopped: return case e := <-r.c: var err error switch req := e.target.(type ) { case *AppendEntriesArgs: e.returnValue, update = r.processAppendEntriesRequest(req) case *RequestVoteArgs: e.returnValue, update = r.processRequestVoteRequest(req) default : err = ErrUnExpectedEvent } e.errc <- err case <-timeoutC: r.setState(Candidate) } if update { timeoutC = afterBetween(DefaultElectionTimeout, 2 *DefaultElectionTimeout) } } }
Candidate循环 处于candidate状态后,Raft节点会向群集广播发起投票,如果竞选成功(超时半数的节点同意),节点角色状态转换为leader。处于candidate状态的节点也可能会收到其它节点发起的投票请求,也可能收到leader的心跳消息,所以candidate状态的节点需要处理RequestVote RPC和AppendEntries RPC。由于采用事件循环,广播RequestVote RPC是并发操作,但返回结果是在事件循环中处理,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 func (r *Raft) candidateLoop () var timeoutC <-chan time.Time var term int var votesGranted int doVote := true for r.State() == Candidate { if doVote { term = r.voteForSelf() votesGranted = 1 r.broadcastRequstVote() timeoutC = afterBetween(DefaultElectionTimeout, 2 *DefaultElectionTimeout) doVote = false } if votesGranted >= r.QuorumSize() { r.setState(Leader) return } select { case <-r.stopped: return case e := <-r.c: var err error switch req := e.target.(type ) { case *AppendEntriesArgs: e.returnValue, _ = r.processAppendEntriesRequest(req) case *RequestVoteArgs: e.returnValue, _ = r.processRequestVoteRequest(req) case *RequestVoteReplyEvent: if r.processRequestVoteReply(req.Peer, req.Req, req.Reply) { votesGranted++ } default : err = ErrUnExpectedEvent } e.errc <- err case <-timeoutC: doVote = true } } }
candidate在发起投票前,首先把当前任期号加1,再给自己投上一票,再向集群发起投票。
1 2 3 4 5 6 7 8 func (r *Raft) voteForSelf () int r.mu.Lock() defer r.mu.Unlock() r.currentTerm++ r.votedFor = r.me return r.currentTerm }
Leader循环 candidate竞选成功后,转换为leader状态。处于leader状态的节点要维护一个心跳定时器,不断向群集广播心跳,同时它可能也会收到集群中其它节点发起的RequestVote RPC和AppendEntries RPC。由于采用事件驱动,广播心跳是并发发起AppendEntries RPC,处理返回结果时都在事件循环中处理,所以还需要处理AppendEntries RPC返回的事件。如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 func (r *Raft) leaderLoop () ticker := time.NewTicker(DefaultHeartbeatInterval) defer ticker.Stop() refreshC := make (chan bool , 1 ) refreshC <- true for r.State() == Leader { var needBroadcastAppendEntries bool select { case <-r.stopped: return case e := <-r.c: var err error switch req := e.target.(type ) { case *RequestVoteArgs: e.returnValue, _ = r.processRequestVoteRequest(req) case *AppendEntriesArgs: e.returnValue, _ = r.processAppendEntriesRequest(req) case *AppendEntriesReplyEvent: err = r.processAppendEntriesReply(req.Peer, req.Req, req.Reply) default : err = ErrUnExpectedEvent } e.errc <- err case <-ticker.C: needBroadcastAppendEntries = true case <-refreshC: needBroadcastAppendEntries = true ticker.Reset(DefaultHeartbeatInterval) } if needBroadcastAppendEntries { r.broadcastAppendEntries() } } }
以上三种角色的事件循环除了完全角色状态转换外,还是作为一个处理框架,后续3个实验会不断完善这个框架。有了这个框架后,需要实现RequestVote RPC和AppendEntries RPC了。
RequestVote RPC 论文Figure 2的右上图已经给出了RequestVote RPC的详细实现,在此转换为golang代码表示:
RequestVote RPC 请求/返回参数结构定义:
1 2 3 4 5 6 7 8 9 10 11 type RequestVoteArgs struct { Term int CandidateId int LastLogIndex int LastLogTerm int } type RequestVoteReply struct { Term int VoteGranted bool }
RequestVote RPC由candidate发起,follower、candidate、leader都有可能收到RequestVote RPC请求,实现如下:
1、如果term < currentTerm,反对投票,并返回currentTerm
在本实验中,可以先不用判断日志是否更新(lab2B才会涉及)。另外这里需要注意一个通用规则,这个规则在论文的Figure 2右下图中给出:
If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1)
这条规则对所有Raft节点都适用,即只要发现比较自己新的term,立即更新自己的term,并将自己转换为follower。
1 2 3 4 5 6 7 8 9 func (r *Raft) updateCurrentTerm (term int , leader int ) r.mu.Lock() defer r.mu.Unlock() r.currentTerm = term r.state = Follower r.leader = leader r.votedFor = VOTED_FOR_NONE }
实现相对比较简单,发送端(candidate):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 func (r *Raft) broadcastRequstVote () req := newRequestVoteArgs(r.CurrentTerm(), r.me, 0 , 0 ) for peer := range r.peers { if peer == r.me { continue } go func (server int , peer int , req *RequestVoteArgs) var reply RequestVoteReply if ok := r.sendRequestVote(peer, req, &reply); !ok { return } target := &RequestVoteReplyEvent{ Peer: peer, Req: req, Reply: &reply, } r.sendAsync(target) }(r.me, peer, req) } } func (r *Raft) processRequestVoteReply (peer int , req *RequestVoteArgs, reply *RequestVoteReply) bool if reply.VoteGranted && reply.Term == r.CurrentTerm() { return true } if reply.Term > r.CurrentTerm() { r.updateCurrentTerm(reply.Term, LEADER_NONE) } return false }
接收端(follower、candidate、leader)实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 func (r *Raft) processRequestVoteRequest (req *RequestVoteArgs) (*RequestVoteReply, bool ) if req.Term < r.CurrentTerm() { return newRequestVoteReply(r.CurrentTerm(), false ), false } if req.Term > r.CurrentTerm() { r.updateCurrentTerm(req.Term, LEADER_NONE) } else if r.votedFor != VOTED_FOR_NONE && r.votedFor != req.CandidateId { return newRequestVoteReply(r.CurrentTerm(), false ), false } r.votedFor = req.CandidateId return newRequestVoteReply(r.CurrentTerm(), true ), true }
AppendEntries RPC 论文Figure 2中左下图有AppendEntries RPC的实现,在此转化为golang代码。
AppendEntries RPC请求/返回参数定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 type AppendEntriesArgs struct { Term int LeaderId int PrevLogIndex int PrevLogTerm int LeaderCommit int Entries []*LogEntry } type AppendEntriesReply struct { Term int Success bool }
为了让问题变得更简单,对于本实验,我们先不用关心请求参数中的 PrevLogIndex、PrevLogTerm、LeaderCommit和Entries(lab2B会涉及)。
AppendEntries RPC 只能由leader发起,发起请求时,我们将PrevLogIndex、PrevLogTerm、LeaderCommit和Entries设置为0,0,0,nil即可,发送端实现为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 func (r *Raft) broadcastAppendEntries () for peer := range r.peers { if peer == r.me { continue } req := newAppendEntriesArgs(r.CurrentTerm(), r.leader, 0 , 0 , 0 , nil ) go func (server int , peer int , req *AppendEntriesArgs) var reply AppendEntriesReply if ok := r.sendAppendEntries(peer, req, &reply); !ok { return } target := &AppendEntriesReplyEvent{ Peer: peer, Req: req, Reply: &reply, } r.sendAsync(target) }(r.me, peer, req) } } func (r *Raft) processAppendEntriesReply (peer int , req *AppendEntriesArgs, reply *AppendEntriesReply) error if reply.Term > r.CurrentTerm() { r.updateCurrentTerm(reply.Term, LEADER_NONE) } return nil }
follower、candidate、leader均有可能接收到该RPC请求,由于lab2A并不涉及日志相关,所以接收端实现也比较简单:
1、如果term < currentTerm,返回currentTerm和false,让leader更新自己的term。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func (r *Raft) processAppendEntriesRequest (req *AppendEntriesArgs) (*AppendEntriesReply, bool ) if req.Term < r.CurrentTerm() { return newAppendEntriesReply(r.CurrentTerm()), false } if req.Term > r.CurrentTerm() { r.updateCurrentTerm(req.Term, req.LeaderId) } else { r.leader = req.LeaderId if r.State() == Candidate { r.setState(Follower) } } return newAppendEntriesReply(r.CurrentTerm(), true ), true }
Q&A 为什么要采用事件驱动? 答案很简单,就是为了让并发编程变得更简单。
可以看出以上实现绝大部分都没有对Raft状态进行加锁,让我们的代码不用考虑资源竞争的问题。通过golang语言原生提供的channel特性,将并发操作转换成事件,在事件循环中顺序处理。虽然我们是并发的发起RequestVote RPC和AppendEntries RPC,但对结果处理时,都将其转换成事件发送了channel,在事件循环中对结果进行处理。这样,Raft的状态就只有事件循环所处的线程访问了。
那为什么有些函数,如updateCurrentTerm和CurrentTerm()中又对currentTerm状态的访问进行加锁呢?因为Raft提供的对外API GetState()有可能被其它线程访问的,所以在访问这些状态前需要进行加锁保护。其实也可以将GetState的请求置换成事件,这样,所有的Raft状态就都不用加锁了。
为什么更新任期号时要重置votedFor状态? 在论文Figure2: Rules for Servers给出了一条对所有server适用的规则:
If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1)
这条规则只说了更新任期号时,角色状态需要转换为follower,但为什么要重置votedFor呢?因为任期号变更后,之前的投票就作废了,如果不重置votedFor,会导致下一任期选举时出现非预期行为。
测试结果 最后附上Lab2A的测试结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ go test -v -race --run 2A === RUN TestInitialElection2A Test (2A): initial election ... ... Passed -- 3.0 3 112 33100 0 --- PASS: TestInitialElection2A (2.96s) === RUN TestReElection2A Test (2A): election after network failure ... ... Passed -- 4.4 3 200 42863 0 --- PASS: TestReElection2A (4.42s) === RUN TestManyElections2A Test (2A): multiple elections ... ... Passed -- 5.6 7 780 167586 0 --- PASS: TestManyElections2A (5.56s) PASS ok 6.824/raft 12.986s
参考资料 [1] In Search of an Understandable Consensus Algorithm 6.824 Lab 2: Raft Part2A raft.github.io