上一篇 Lab2A: 选主 中介绍了Raft选主的实现,本篇介绍Raft日志复制的原理和实现。实验二共包含四个子实验:
本文是第二个子实验,需要实现Raft日志复制。由于Raft的强领导人特性,命令都是通过Leader顺序追回到日志中,然后通过Leader复制到各Follower中,由于Raft的日志安全特性,使得集群节点中的日志最终达到一致。在开始实验前,先阅读以下材料:
- 阅读论文:In Search of an Understandable Consensus Algorithm,以下简称论文。
- 阅读实验指导:6.824 Lab 2: Raft Part2B
- 阅读Students’ Guide to Raft,本文中介绍了些论文中没有给出的实现细节。
Raft日志复制是Raft协议最核心的部分,也是最难的部分。论文中将日志复制和安全性是分开讨论的,实现的时候我们需要将这两部分结合起来。另外论文中对一些实现细节是空白的,如日志冲突的优化,这要求我们要实现的时候要考虑各种边界问题。
基本原理
选主成功后,Leader就开始接收客户端的请求。每个请求是能够被复制状态机执行的命令(command)。Leader首先将命令作为一个日志记录(entry)追回到日志中,然后并行地向集群中的其它节点发起AppendEntries RPC请求。当日志记录被安全复制到其它节点后,Leader将该记录应用到状态机中,并将状态机执行的结果返回给客户端。如果Follower崩溃或网络丢包,Leader会不断重试向Follower发送AppendEntries RPC,走到Follower最终全部保存了Leader的日志记录。
以上就是Raft日志复制的全部流程,它涉及到很多细节,这里我主要说一下日志记录和安全性。
日志可以理解成是一个包含日志记录(entry)的列表,每个日志记录包含了三个信息:
- Term:Leader生成日志记录时任期号
- Index:日志记录在日志中的索引号
- Command:可以被状态机执行的命令
Term和Index主要用于日志一致冲突检测(下面会介绍);Command是上层状态机的一个概念,Raft其实并不理解,只是Raft需要解决Command的一致性问题,所以Raft把Command当成一个上下文参数存储到一个日志记录中,当Raft认为一个日志记录在集群中已经达成一致后,Raft只是将这个Command再较交给状态机去执行。这个地方说的达成一致,就是指日志已经被安全复制。
在讨论什么叫安全复制之前,先直接抛出Raft给出的安全性保证,这些保证在论文中的详细论述和证明,在此不一一展开
安全性
选举安全(Election Safty)
每一届任期最多选举出一个领导人。根据上一篇中可知,每一届任期要么选举出一个领导人,要么发生投票分裂,选举超时后在下一任期重新选举。
在Lab2A中,我们RequestVote RPC接收者的实现中,我们遗留以下逻辑:
If votedFor is null or candidateId, and candidate’s log is at least as up-to-date as receiver’s log, grant vote.(§5.2, §5.4)
我们只实现了前半部分,由于Lab2A中没有涉及到日志,所以没有判断后半部分逻辑。接收者之所以要判断竞选者的日志是否至少比自己的日志更新,是因为这样可以保证赢得选举的节点至少包含了最新提交的日志。可以这样,选举要获取半数以上的节点同意,也就是半数以上的节点日志至少没有竞选者新,而提交的日志也是要经过半数以上的节点复制成功才能提交,所以竞选者一定这半数以上节点中的某一个。
只能领导人追加日志(Leader Append-Only)
领导人不能覆盖或删除日志中的记录,它只能追回新的日志记录。这是因为只有Leader能才接收客户端请求,接收客户端请求后,只是把请求Command作为日志记录追加到日志中。
日志匹配(Log Matching)
如果不同日志中的两个日志记录具有相同的日志索引号和任期,那么在这个索引号以及之前的日志记录均是相同的。在5.3节中,将日志匹配展开成日志匹配属性(Log Matching Property),包含两条:
- 如果不同日志中的两个日志记录具有相同的Index和Term,那么它们存储了相同的Command。
- 如果不同日志中的两个日志记录具有相同的Index和Term,那么它们之前的日志记录都是相同的。
第一个属性比较容易证明,因为每个Leader的任期是惟一的,在同一个任期内,日志记录是追加的,也就是说Leader追加的日志记录都是惟一的。第二个属性涉及到日志一致性检测(log consistency check),日志一致检测是在AppendEntries RPC中完成的。Leader在向Follower发送Append Entries RPC请求时,会包含上一次同步日志的最后一个日志记录的Index和Term,如果Follower中能找到这个Index和Term,则从这个Index的下一个位置开始同步;如果没有找到,则拒绝,直到找到日志的冲突位置再同步,后面会详细日志一致性冲突检测。
领导人完整性(Leader Completeness)
如果一个日志记录在某个任期被提交,则该日志记录会出现在具有更高任期的领导人日志中。一旦被提交,那么这条日志记录必定在半数以上节点中,由选举安全性,只能是这半数节点中的某一个才能被选为Leader,成为Leader后,由于只能领导人追加日志,根据日志匹配安全性,Leader的日志会覆盖Follower中有冲突的日志,使得最终Leader和Follower中的日志达成一致。
状态机安全性(State Machine Saftey)
如果一个server将某个日志索引的日志记录应用到了状态机,那么其它server在同一个日志索引处也会应用到相同的日志记录。这条安全性实际上是由上一条安全性推导出来的。因为在日志中某个索引的日志记录一旦被提交,那么这条日志记录将会出现在后续的任期中,最终会复制到其它节点上,再应用到本地状态机中。
安全复制
如何判断日志记录被安全复制呢?在当前任期,日志记录在半数以上节点复制成功,称为安全复制,也称该日志记录为已提交。注意,这里说的是当前任期,这个很重要,下面有个case会介绍为什么从之前的任期不能提交日志记录。
Leader中为每个server维护了一个状态matchIndex,表示server当前已成功复制日志记录的最高日志索引。这个状态在Leader选主成功后初始化为0,每次向其它server发起AppendEntries RPC收到Success返回后,更新matchIndex。那如何判断半数已上节点成功复制了日志记录呢?论文中Figure 2右下图Rules for servers针对Leader的规则中给出了形式化的描述:
If there exists an N such that N > commitIndex, a majority
of matchIndex[i] ≥ N, and log[N].term == currentTerm: set commitIndex = N (§5.3, §5.4).
由于matchIndex是表示server当前已复制成功日志记录索引号,我们将matchIndex[]逆序排序,在半数以上节点的位置即为commitIndex,如果半数以上定义为:
1 | quorum = len(servers) / 2 + 1 |
那么newCommitIndex = sort(matchIndex[])[quorum-1],注意matchIndex的索引是从0开始的。如果得到的 newCommitIndex 比当前记录的commitIndex大,说明我们有新的日志记录需要提交。
日志一致性冲突检测
日志一致性冲突检测目的检查出Leader和Follower发生日志冲突的位置,是在AppendEntries RPC中完成,当检测出日志冲突的位置后,Follower会使用Leader的中日志从冲突位置本地日志。
Leader为每个Follower都维护了一个nextIndex状态,表示Follower中下一个要追加日志的索引号。这个状态在节点成本Leader时初始化为节点最近一次日志记录的Index。Leader在发起AppendEntries RPC请求时,请求参数中包含了prevLogIndex和prevLogTerm,其中prevLogIndex=nextIndex-1。Follower在接收到AppendEntries RPC请求后,先检测prevLogIndex的索引位置是否找到Term=prevLogTerm相同的日志。
- 如果找到,说明Leader和Follower的日志已经匹配,Follower移除prevLogIndex之后的日志,并将entries追加到prevLogIndex之后。如果leaderCommit > commitIndex,设置commitIndex=min(leaderCommit, 最后一个日志记录的Index)
- 如果未找到,说明Leader和Follower的日志仍然冲突,返回false,Leader收到返回后将对应Follower的nextIndex减1,重新发起AppendEntries,直到日志匹配。
可以看出如果某个Follower长期宕机重启后,将会滞后很多日志,每次发现冲突后,Leader只对nextIndex减1,会发生O(N)次Append Entries RPC交互,其中N为滞后的日志数。在实际生产环境中这是可能发生的,论文作者提出了一种优化方案,但很多实现细节没有给出,Students’ Guide to Raft给出了详细优化方案实现,如下:
在AppendEntriesReply结构中增加conflictIndex和conflictTerm。
- 如果Follower在prevLogIndex日志索引处没有日志记录,返回ConflictIndex = len(log),并且conflictTerm = None。
- 如果Follower在prevLogIndex日志索引片有记录,但term和prevLogTerm不匹配,并搜索冲突任期term中的第一日志记录entry,conflictIndex = entry.Index, conflictTerm = entry.Term
- Leader收到返回后,首先在日志中搜索任期为conflictTerm的最后一条日志记录entry,如果找到,另nextIndex=entry.Index,如果没有找到则设置nextIndex=conflictIndex.
需要说明的是,对于步骤1,为后面日志压缩做准备,不要使用log的索引号作为日志记录的索引号,应该将ConflictIndex设置为最后一条日志记录的Index+1。
从之前的任期提交日志记录
论文中作者花了比较大的篇幅解释了为什么*不能从之前的任期提交日志记录,即使日志记录已经复制到了半数已上节点上。这个地方翻译一下作者给出的case,如下图:
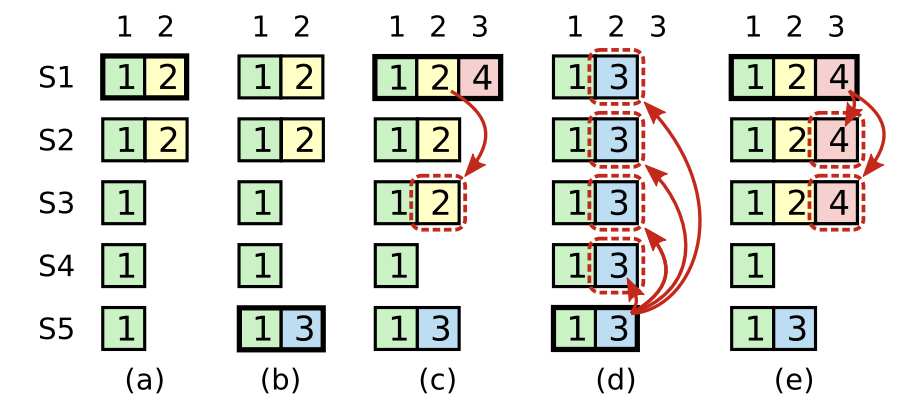
(a)中S1是领导人,并且部分复制索引为2的日志记录。在(b)中,S1崩溃;S5收到来自S3、S4再加上自己的一张选票成为领导人,并且在索引为2的位置接收了一个不一样的日志记录。在(c)中,S5崩溃;S1重启,并被选举为领导人,开始继续复制日志,此时,索引为2日志记录已经复制到了半数以上节点,但它仍然不是已经提交的日志记录。如果S1在(d)中崩溃,S5仍然可能被选举为领导人(S2、S3、和S4投票),然后会将自己term=3的日志记录覆盖其它节点索引为2的位置。但是,如(e)如示,如果S1在崩溃前,在它当前的任期复制日志记录到半数以上节点,那么这个日志记录被称为已提交的(S5不能再赢得选举)。这个时候,当前日志记录以及之前的所有日志记录也都是已经提交的。
实现
Lab2B实现主要有三个部分,主要是:
- 完善RequestVote RPC,使其满足选主安全。
- Leader事件循环实现接收客户端命令逻辑。
- 完善AppendEntries RPC。
前两个都比较简单,第三个会涉及到比较多的细节,比较日志一致性冲突检测,对nextIndex、matchIndex、commitIndex、appliedIndex状态的维护等。在介绍实现之前,需要先理解Lab2B需要关注的Raft状态。
Raft状态
请看次回顾一下Figure 2中左上图,Lab2B中我们需要关注以下状态:
| Raft状态 | 说明 | 适用角色 |
|---|---|---|
| log[] | 日志,其中每项称为一个日志记录,每个日志记录包含任期(Term)、日志索引(Index)以及状态机命令(Command) | 全部 |
| commitIndex | 最近提交的命令所处的日志索引,初始化为0,单调递增 | 全部 |
| lastAppied | 最近应用到状态机的日志记录对应的日志索引,初始化为0,单调递增 | 全部 |
| nextIndex[] | 对每个server维护的下一次复制日志记录的索引位置,初始化为Leader的最近一个日志记录索引+1 | Leader |
| matchIndex[] | 对每个server维护的当前已复制日志记录的索引位置,初步化为0,单调递增 | Leader |
LogEntry结构
为后续日志压缩实验做准备,这里我不使用log数组的索引作为日志的索引,而是单独使用一个Index表示日志记录在日志中的索引。一个日志记录还包括追加日志时的任期和状态机命令,定义如下:
1 | type LogEntry struct { |
Start
Start的实现简单,由于采用事件驱动,只需要将命令包装成一个事件,然后将事件发送到事件循环中处理即可。在Leader的事件循环中添加对命令事件的处理,处理逻辑也比较简单,主要包括:
1、生成一个新的日志记录
2、追回到日志中
3、Leader写入日志相当于日志已经复制完成,需要更新nextIndex和matchIndex
1 | type CommandArgs struct { |
RequestVote RPC
上面已经提到,我们只需要在接收端添加一个投票限制条件:判断候选者的日志是否至少比接收方日志新。怎么判断呢?论文中5.4.1给出了明确说明:
If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
比较好理解,首先判断任期(Term),任期越大的日志越新,任期号相同,比较日志索引大小,索引越大的越新。代码实现就比较简单了:
1 | func (r *Raft) processRequestVoteRequest(req *RequestVoteArgs) (*RequestVoteReply, bool) { |
AppendEntries RPC
为了做日志一致检测优化,AppendEntries RPC返回中增加了两个返回参数ConflictIndex和ConflictTerm,AppendEntriesReply结构定义如下:
1 | type AppendEntriesReply struct { |
在Leader循环开始前,我们需要初始化nextIndex和matchIndex,如下:
1 | func (r *Raft) leaderLoop() { |
Leader在发起AppendEntries RPC请求时,需要带上上一次同步的index和term,还有最近提交的index以及本次要同步的日志记录。接收端返回后要更新nextIndex和matchIndex。如果越过半数以上的日志复制成功,则提交日志,交应用到本地状态机中。
1 | func (r *Raft) getPrevLogIndex(peer int) int { |
follower、candidate、leader均有可能接收到该RPC请求。接收端先进行冲突检测,如果冲突检测通过,将会截断冲突的日志,然后从冲突索引处追加日志,如果leaderCommit大于本地commitIndex,还需要提交日志,并应用到本地状态机中。实现如下:
1 | func (r *Raft) processAppendEntriesRequest(req *AppendEntriesArgs) (*AppendEntriesReply, bool) { |
Q&A
Follower何时提交日志?
Leader维护了一个最近提交的日志索引状态commitIndex,Leader在接收客户端请求后,会先将命令追加到本地日志,然后发起AppendEntries RPC请求,当收到半数以上的节点完成复制后,Leader提交日志(更新commitIndex),并将命令应用到本地状态机。下次Leader再次发走AppendEntries RPC时,commitIndex已经变更,Follower接收到AppendEntries RPC请求后,会将本地commitIndex和leader的commitIndex对比,当发现commitIndex < leaderCommit时,Follower才会提交日志,并将命令应用到本地状态机中。
从以上流程可以看出,客户端提交一个请求后,Follower需要至少第二个AppendEntries RPC到来时才有可能提交客户端的请求。为什么这里说至少第二次,因为如果Follower的日志比较滞后,那么可能需要多少AppendEntries RPC才能完成同步。
truncateLog什么情况下会出现prevLogIndex比commitIndex小?
由于并发操作,以及网络交互的顺序是无法保证的。这种情况发生在:Leader先后对同个follower发起两次AE RPC,第二次AE RPC的entries大于第一次。Follower先收到第二个AE RPC请求,然后回复,Leader在收到半数以上节点日志复制成功后,提交日志,并发起第三次AE RPC请求,时此的commitIndex已经更新。Follower收到第三次AE RPC请求后,在本地提交了日志。随后Follower才收到第一次AE RPC的请求,此时,prevLogIndex就会比commitIndex小。
日志一致性冲突检索优化是如何工作的?
第1步中,如果Follower中根本没有prevLogIndex索引的日志记录,说明当前Follower日志缺失,此时只需要将ConflictIndex设置为Follower最后一条日志记录的Index+1,也就是日志缺失的情况下,我们默认认为Follower中现有的日志跟Leader是不冲突的,这样可以一次将冲突索引回退到Follower最后一个日志索引的下一个位置。
第2步中,如果Follower中prevLogIndex索引的日志记录存在,但日志记录的term和prevLogTerm不匹配,则说明这个任期之前的所有日志记录均不匹配(回头看看日志匹配属性),这时我们找到冲突任期的第1个日志记录作为冲突位置,下次将会检测冲突位置的前一个位置,也就是前一个任期的最后一个位置是否和Leader匹配,如果不匹配,会再次进行该步骤。
第3步中,最大的疑问就是Leader为啥先查找冲突任期的最后一个日志记录?这相当于是一个优化,如果在Leader中找到冲突的任期,这种情况只能说明这个冲突任期内Leader的日志数比Follower短(根据日志匹配属性,如果大于等于的话就不会出现冲突了),此时以Leader在该冲突内的任期的最后一个日志记录索引号+1作为Follower的nextIndex即可。相当于下次检测Leader冲突任期内的最后一个日志记录是否匹配。
测试结果
最后附上Lab2B的测试结果
1 | go test -v -race --run 2B |
参考资料
[1] In Search of an Understandable Consensus Algorithm
[2] 6.824 Lab 2: Raft Part2B
[3] Students’ Guide to Raft