在Go语言中,string是一种非常重要的数据结构。了解string的内部实现原理,有利于我们写出更高效的代码。本篇文章首先介绍string的实现原理,然后介绍string、bytes、runes和characters之间的关系,同时引出字符篇码Unicode和UTF-8,最后介绍使用string应该注意的一些问题。
先来看下面两个例子。
示例一
1 | str := "中文abc" |
示例二
1 | str := "中文abc" |
上面例子中,%x 表示以16进行输出,%#U 表示输出Unicode字符的码点(code point)和其表现。你知道上面例子输出的结果是什么吗?如果理解了上面例子的输出,那基本了解了Go语言内部是如何实现的string,先来看string的内部数据结构。
数据结构
在示例一中,你会发现len(str)并不是字符个数,而是字节数,字符中和文各占3个字节,a、b、c各占一个字节,所以len(str)为9。这里我们先忽略为啥字符中和文使用三个字节表示。我们先来看下string的内部结构是什么样子,它定义如下:
1 | type _string struct { |
可以看出,string的内部结构其实比较简单,由一个byte指针和byte大小组成,跟slice的实现很像,但没有capacity属性。这是因为在Go中,string是只读的,一旦定义会就不能修改,所以string没有扩容操作。由于是string是只读的,在对string做切片操作时,会共享同一份底层存储空间,所以分片操作效率非常高,如下图:
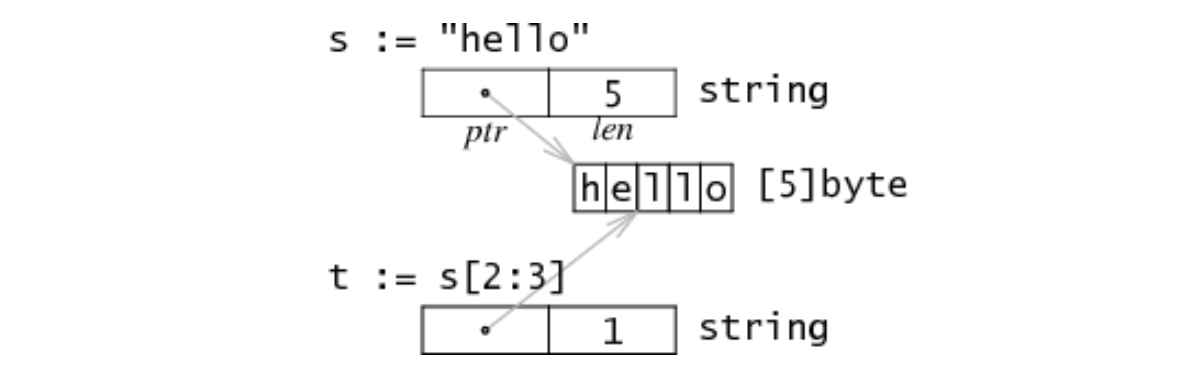
图片来自: Go Data Structures
string内部是由只读的byte数组组成,同时记录了byte数组的长度。再回到示例一,len操作是获取string的字节数,索引操作为字节所处的位置,时间复杂度都是O(1),效率非常高。
string是只读的,那我们要对string进行修改怎么办呢?这涉及了string和byte slice的转换。由于byte slice是允许修改的,它们之间的转换都会生成深拷贝操作(编译器对部分情况做了优化),所以当我们在对比较大的string或byte slice之间转换时,应该明白它们转换的开销。转换操作比较简单,如下:
1 | oriStr := "中文abc" |
string、character、bytes和runes之间的关系
上节介绍了string的内部实现,了解string是由byte数组组成。但我们单看string中的一个字节是没有什么意义的。我们讲string是由字符组成,那字符跟bytes又是什么关系呢?
这里我们不得不引入字符集的概念,目前使用最多的是Unicode字符集。Unicode字符集定义了每个字符的编码,被称为码点(code point),这里不打算展开讨论,可以简单理解码点是字符的惟一编码,如字符中的Unicode编码为\u4e2d,a是Unicode编码为\u0061。
在Go语言中,使用rune惟一表示一个字符,它是一个int32的别名,用于存储字符的码点。示例二for…range循环中,每次迭代返回的第二个值就是rune,通过%#U可以输出字符的Unicode编码和表现。
但在示例一中我们知道字符中由三个字节组成,在内存用十六进制表示为e4 b8 ad,为什么内存中的表示和Unicode编码不一样呢?
这里有一个重要的概念:Unicode只定义了字符集,但并没有规定一个字符在内存或磁盘中应该如何存储,换句话说字符在内存或磁盘中的存储方式是对Unicode码点的一种编码方式。
熟悉UTF-8的知道,字符中的Unicode为\u4e2d,它的UTF-8编码为e4b8ad。UTF-8是Unicode的一种编码实现,它表示一个Unicode字符至少使用一个字节表示(一字节为8个bit),同理UTF-16表示一个Unicode字符至少用两个字节表示。关于更多Unicode和UTF-8的细节请参考另一篇文章:每个程序员都应该知道的字符编码。
关于字符编码,你惟一需要知道的就是需要知道字符的编码方式。这就好比给你一段密文,但不给你密钥,你是无法解开密文的。同样,字符在内存或磁盘中是经过编码的,编码后的字符使用byte表示,至于使用多少个byte,不同的编码方式是不一样的。那上面示例中,字符串中文abc是使用的什么编码方式呢?从示例一中对字符串的十六进制字符输出,我们知道它是使用的UTF-8编码。
Go语言规定,Go源代码使用UTF-8编码。当我们使用字符串字面量字义一个string时,Go编译器对源代码进行编译时,就会对字面量按UTF-8进行编码后存储到内存或磁盘中。但千万不要认为,Go中的string都是使用UTF-8编码的。string的内部实现是一个byte数组,它只是对字符编码后的存储,跟具体的编码方式没有任何关系,string可以存储任何值,只有采用字面量声明的string才是使用UTF-8编码的。
比如,我们可以在string中存储任何值:
1 | str := "\xbd\xb2\x3d\xbc" |
上面例子中,采用转义\xNN的方式展示指定了string中每个byte存储的值,但我们输出其内容时,会显示乱码,因为它不能表示合法字符。
有了字符编码,必定也有对应的字符解码,那示例中是什么时候解码的呢?
在示例二中的for…range循环时,就会对string进行UTF-8解码操作,我们使用标准库中的encoding/utf8包等价实现如下:
1 | str := "中文abc" |
最后我们来回答一下,string,character、bytes和runes之间的关系。
这里我们需要从两个维度来看:
- 从表现层面看,string是由字符组成,字符是string的最小单位。
- 从实现层面来看,字符是由byte组成,byte是字符以某种编码方式在内存中的一种呈现,字符编码后最小的存储单位是byte;为了让每个字符有惟一的表示,Go中使用rune惟一表示一个字符。
需要注意的问题
分片操作与垃圾回收
和slice一样,string在进行分片操作时,会引用共享的byte数组,只有当共享的byte数组没有被任何string引用时,才会被垃圾回收器回收。如果string中保存了大量数据,但我们在进行分片操作时,只使取了很少一部分,我们需要将这部分数据copy出来,以让垃圾回收器回收空间以释放内存。
string和byte slice转换开销
由于字符串是只读的,当我们对string和byte slice进行转换时,会发生深拷贝操作。当string或byte slice存储的数据量比较大时,进行转换时需要明白你当前是否在做正确的事情。Go中编译器对string和byte slice转换也做了很多优化,在Go 101: Strings in Go有详细介绍。
总结
- string的内部数据结构是只读byte数组,并记录了数组的大小。在对string进行索引操作时,是获取对应位置的byte,而不是字符。
- string是由字符组成,字符在内存中表示时,涉及到对字符的编码,编码后的字符串使用bytes表示,至于使用多少个byte表示一个字符,跟具体的编码方式有关。Go字面量定义的字符串都是使用UTF-8进行编码的,但并不是说Go中所有的string都是使用UTF-8编码,string可以存储任何值,跟具体的编码方式没有什么关系。
- for…range对string操作时,会对bytes按UTF-8进行解码操作,返回每个字符的起始索引位置以及字符,在Go中字符的惟一表示使用rune存储,rune是int32的别名。
- 在对string进行分片操作时,注意垃圾回收问题,避免不必要的内存开销;在对string和byte slice进行转换时,会进行深拷贝,注意计算或内存开销。
参考资料
[1] Strings, bytes, runes and characters in Go
[2] Go Data Structures
[3] Go 101