map又称映射表或关联数组,是一种常用的数据结构。它由一组<key, value>组成,每个key只出现一次。Go语言原生支持了map数据结构,正如 Go maps in action 中所说:
One of the most useful data structures in computer science is the hash table. Many hash table implementations exist with varying properties, but in general they offer fast lookups, adds, and deletes. Go provides a built-in map type that implements a hash table.
简单来说就是因为 hash table 是非常有用,并且提供了快速的查找、添加、删除特性,所以Go语言提供了map类型,它的底层是使用的hash table。
刚接触Go语言时,有两点比较困惑:
- 对map排序时,需要先对取出map中所有的key,对key排好序后,通过排好序的key查找value。
- 遍历map时,每次得到的结果顺序都不一样。
随着对Go语言的了解,虽然这两个问题早以有了答案,但仍然想要了解一下map的内部实现原理,于是便有了这篇文章。
在这篇文章中,先简要介绍map的基本用法,再深入map的内部实现原理,最后介绍使用map时需要注意的问题。
基本用法
Go语言中map的用法比较简单,简述如下:
- 构造:
m := map[key]value{}或m := makkey]value, len) - 插入/更新:
m[k] = v - 查询:
v := m[k]或v, ok := m[k] - 删除:
delete(m, k) - 遍历:
for k, v := range m - 大小:
len(m)
对于key,必须支持==操作,另外需要注意的是,声明一个map,如果没有初始化,插入时会panic,如下:
1 | var m map[string]string |
更多具体例子参考:Go by Example: Maps
数据结构
hash table的底层是一个bucket数组,每个bucket用于存储<key, value>。其核心原理是通过一个hash函数,将key映射到一个bucket中。如果有两个不同的key映射到同一个bucket,这种情况被称为hash冲突。当出现hash冲突时,通常使用链表法或开放地址法,Go语言中map使用的是链表法。具体是将bucket实现为一个链表,hash冲突时,链接一个新的bucket。
以下代码分析基于Go语言版本:1.19 linux/amd64。
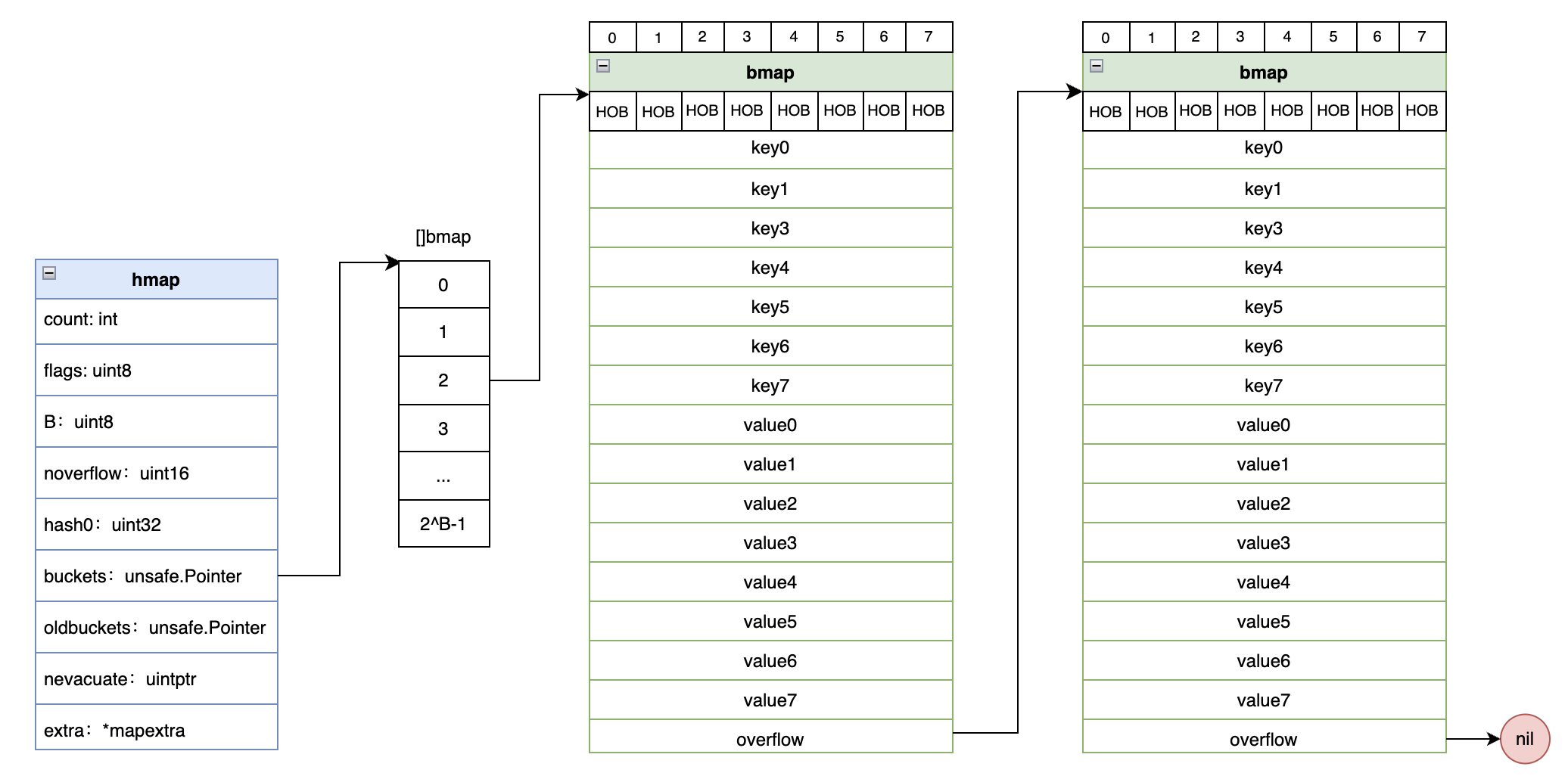
map的结构体为hmap定义为(见src/runtime/map.go):
1 | // A header for a Go map. |
这里面涉及一些细节,这里我们只需要关注以下字段:
- count:map中元素的个数
- B:bucket的数量为2^B
- buckets:指向bucket的指针
- oldbuckets:指向之前的bucket指针,数据迁移时会用到,下面会讲到
每个hmap中有2^B个bucket,buckets指向这个数组。对于每个key,通过hash函数后,会取hash后的低B位,然后决定这个key落到哪个bucket中。通常的实现是一个bucket存储一个kv,但Go语言中一个bucket最多可以存储8个kv。bucket的数据结构由bmap表示,结构如下
1 | // A bucket for a Go map. |
这个一个表面的结构,编译器在编译后会创建一个新的结构体,大致如下:
1 | type bmap struct { |
bmap的前8个字节存储了bucket中每个key进行hash的高8个bit位,主要是为了实现快速查找,定位某个key的存储位置。接下来存储了8个key,然后再存储8位value,最后一个是overflow指针,指向下个bmap。至于为什么不采用8个key-value的存储方式,如key0/value0/key1/value2…,Inside the Map Implementation给出的解释是可以节省内存空间,减少不必要的padding。比如:
1 | map[int64]int8 |
如果采用key/value的存储方式,每一个value后面都需要padding,而采用key0/key1/…/key7/value0/value1/…/value7的方式,每个key是按字对齐的,所有的val也是按字对齐的,并不需要padding,所以节省了空间。
我们最后用一个图来描述一下hmap的整体结构:
查找
查找是其它操作的基础,所有操作都是要先找到对应的位置,才能进行添加/更新/删除操作。所以这里先介绍查找,查找的过程如下:
1、key经过hash函数后,会得到一个64bit的hash值(目前基本上都是64位机)。
2、取hash值的低B个bit位计算出key应该落在哪个bucket中。
3、取hash值的高8位,在bucket的tophash数组中查询。
4、如果tophash[i]中存储的hash值与当前key的hash值高8位相等,则获取bucket中第i个位置的key进行比较。
5、如果相等,说明已经找到,否则从overflow指向的bucket中进行查找。
下面以B=5,bucket数量为2^5=32个,一个key经过hash计算后得到结果是:
1 | 10010111 | 000011110110110010001111001010100010010110010101010 │ 01010 |
hash的低5位是01010,值为10,所以这个key会落到10号桶(从0开始),高8位为10010111,值为151。查找时会遍历这个bucket的tophash数组,找到tophash[i]为151对应的i位置,然后取出进行比较,如果key相同,说明已经找到;如果key不相等,继续遍历;如果当前bucket中没有找到,会遍历overflow指向的bucket。
key的查找过程如图所示:
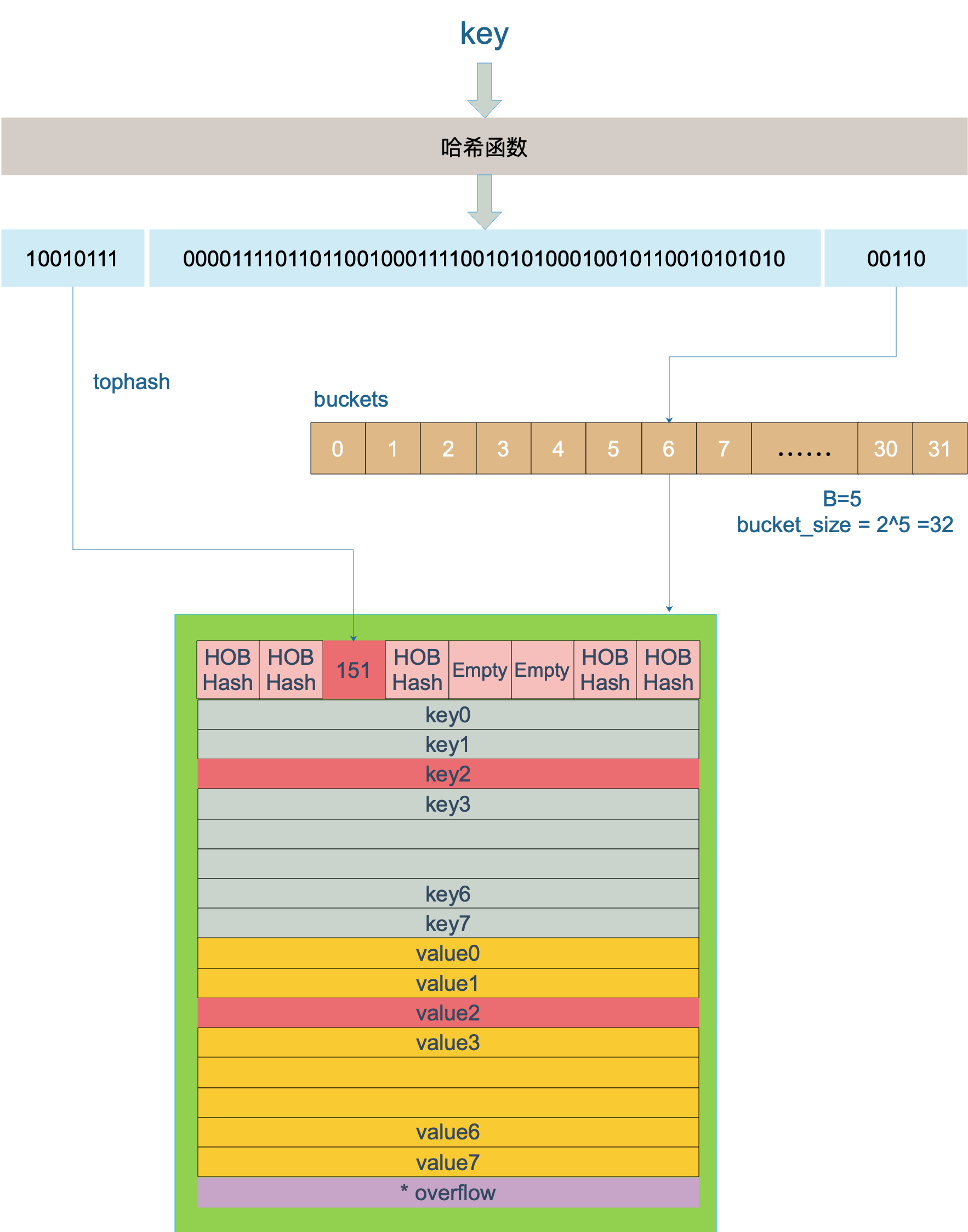
图片来源:深度解密 Go 语言之 map
添加/更新
添加和更新过程类似,主要区别是,找到key所在的位置后,如果key存在,则为更新,如果不存在,则添加。主要过程如下:
1、根据key计算出hash值。
2、取hash值的低B位来确定bucket所在的位置。
3、遍历bucket的tophash数组,查找key是否存在,如果存在直接更新。
4、如果key不存在,则从bucket中寻找空余位置插入。
删除
删除元素同样是先要找到key对应的元素,如果元素存在则把元素从对应的bucket中清除,如果不存在,什么也不做,所以delete(m, key)在key不存在时,不做仍然操作。
扩容和数据迁移
上面在对map做增、删、改、查操作时,没有考虑扩容的情况。之所以单独介绍扩容,是为了让上述过程更容易理解。map的扩容对应用是透明的,当在满足以下任何一个条件时,会触发扩容操作:
1、负载因子大于6.5时,即平均每个bucket存储的键值对超过6.5个。
2、overflow的bucket数量大于2^15 = 32768。
负载因子 = 键数量 / bucket数量。负载因子太大,说明冲突严重,存取效率低。第二种overflow的bucket数量过多,可能是因为负载因子过大,也可能是负责因子过小。当map中不断插入,然后又删除大量元素后,可能出现不满足条件1的情况,这种情况下空间利用率其实是比较低的,这个时间第2个条件就起作用了。
整个扩容过程可以概括为:
1、申请更大的一片存储空间。
2、将再有的key-value对重新计算hash值,存储到新的空间中。
3、释放不再使用的空间。
由于数据迁移过程,数量量可能非常大,上述操作过程会非常耗时,这会影响到map的性能,Go语言中map的扩容在实现时采用增量的方式进行,每次在进行更新操作(插入/修改/删除)时,迁移2个bucket。
扩容
当满足上面任何一个扩容条件时,先进行扩容操作,这个主要在runtime/map.go中hashGrow函数中完成,主要逻辑为:
1、判断是增量扩容还是等量扩容,如果是增量扩容,对B += 1
2、将hmap中的oldbuckets指向原buckets数组
3、申请新的buckets空间
4、将hmap中的buckets指向新的buckets数组
这样就完成了新老buckets数组的交接,然后进行数据迁移,数据迁移是将oldbuckets数组中的键值对逐步搬迁到buckets数组中,待oldbuckets数组中的所有键值对搬迁完毕后,就可以安全释放oldbuckets数组了。
根据上述的两种扩容条件,扩容分为:
- 增量扩容:针对上面的条件1,每次扩容后,bucket数量增大为原来的两倍,即:B += 1。
- 等量扩容:针对上面的条件2,每次扩容,bucket数量不变,但重新组织了key/value,使得bucket具有更高的使用率。
数据迁移
数据迁移是增量式的,Go语言中map在实现数据迁移时,实现的比较巧妙,这里不想讨论代码细节,只说一下大概思路:
对于等量扩容的数据搬迁相对简单些,因为bucket数量没有改变,相同的key在经过hash计算后,在新老bucket中的位置是相同的。比如原因key原来在0号bucket,等量扩容后,仍然在0号bucket,只需要遍历老的bucket(包括overflow),对每一个key/value,迁移到新的bucket即可。
对于增量扩容就没那么简单了,由于bucket扩容为原来的两倍(B += 1),老bucket中的key在新bucket数组中可能在相同索引号,也可能不在,这取决于key的低第B位(扩容后的B)是0还是1,怎么理解呢?
定位key在哪个bucket是根据key的hash值的低B位决定的,当扩容后,B加1,如果key的hash值的第B位为0则低B位跟扩容前的低B位是一样的;如果第B位为1,则key的低B位值为扩容前低B位的值加2^(B-1)。
例如,原始 B = 2,1号 bucket 中有 2 个 key 的哈希值低 3 位分别为:010,110。由于原来 B = 2,所以低 2 位 10 决定它们落在 2 号桶,现在 B 变成 3,所以 010、110 分别落入 2、6 号桶。
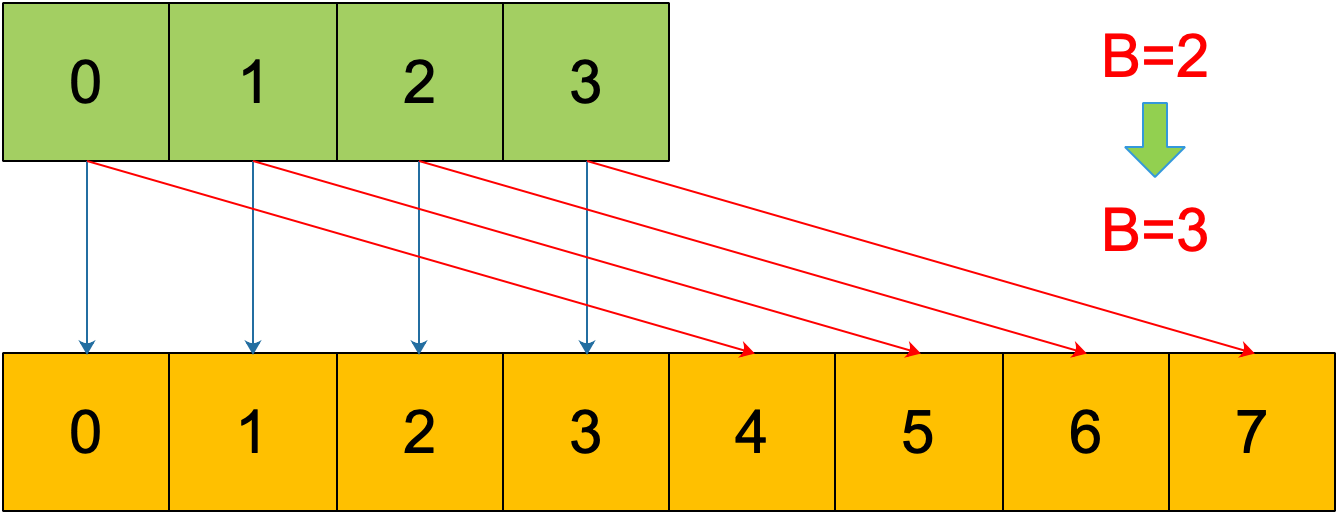
图片来源:深度解密 Go 语言之 map
这便是Go语言中map实现的精巧之处,扩容后,通过key哈希后的第B个bit位,便可以找到老bucket和新bucket的一种关系。有了这个关系,在对oldbucket中的某个bucket迁移时,遍历bucket中的所有key/value,重新计算key的hash值,如果hash值的第B个bit位为0,则迁移到新bucket数组中的相同索引号中;如果为1,则迁移到位B位的值的索引位置。
遍历
通过上面对map实现原理的分析,遍历map是不能保证顺序的。另外,由于扩容操作,同一个bucket中的key在扩容后,可能被迁移到新的bucket中,所以遍历map时,并不是稳定的。那是不是说map不扩容,它输出的顺序就是稳定的呢?Go为了让程序员彻底放弃这个依赖,遍历时,会随机选择一个bucket和offset,你会发现每次遍历出来的顺序都是不一样的。
对于应该层面来讲,了解上面的特性就够了。但还想补充一下在遍历正在扩容时的map时,Go是如何实现的。同样,我不想太深入代码细节,这里只给出大概的逻辑:
1、通过随机生成的bucket索引,定位到具体的bucket。
2、根据当前bucket的索引号,可以找到对应老的bucket。
3、如果老bucket未迁移,遍历老bucket中将会迁移到该新bucket中的key/value。
4、遍历下一个bucket,直到所有bucket遍历完成。
遍历正在扩容的map时,最关键在于第3步。其根本原因在于扩容前的一个bucket中的key会分散到扩容后的两个bucket中,至于到底落到哪个bucket,取决于key的hash值第B个bit位是0还是1。遍历一个bucket时,需要先检查对应的老bucket是否迁移,如果没有迁移,只需要遍历老bucket中应该落在当前bucket的key/value即可。
注意的问题
- map是非线程安全的,map在实现时做了多线程访问检测,如果出现多线程访问,会panic。
- map的遍历是结果随机的。
- 对于值为nil的map,写入会panic,见上面创建map的两种方法。
- map会对value小于128B的非指针类型的值做GC优化,由于map扩容时bucket只增不减,即便删除对应的key,内存依然不会释放。
参考资料
[1] Inside the Map Implementation
[2] 深度解密 Go 语言之 map
[3] Go maps in action
[4] hash table