本文翻译自 Google Technical Writing Courses,是Google推出的技术写作课程,该课程包含两个部分,本文是第一部分。
单元测试的实践与思考
从个人经历过的多个团队中,发现有一个共性是:极少有团队注重单元测试。甚至当我想在团队中倡导单元测试时,有个研发经理跟我表达单元测试没有任何意义的结论。我不知道这是个人的不幸呢,还是整个中国互联网公司的现状如此?
本文算是给单元测试”正名”,介绍单元测试的意义以及编写可测试代码的一些原则和思考。
什么是单元测试
单元测试是一段自动化的代码,这段代码调用被测试的工作单元,之后对这个单元的单个最终结果的某些假设进行检验。单元测试几乎都是用单元测试框架编写的。单元测试容易编写,能够快速运行。单元测试可靠、可读、并且可维护。只要产品代码不发生变化,单元测试的结果是稳定的。
工作单元是指从调用系统的一个公共方法到产生一个测试可见的最终结果,其间这个系统发生的行为总称为一个工作单元。一个单元可以小到只包含一个方法,也可以大到包括实现某个功能的多个类和函数。
CentOS搭建CodeServer环境
Code Server是一个基于VSCode实现的开源的云端IDE,只要能联网,就可以通过浏览器进行访问,无需安装,十分方便。本文主要介绍如何在CentOS 8中安装Code Server。
依赖环境
- 2GB RAM
- 需要root权限,对于非root账号,需要sudo权限
- 需要安装nginx
Go并发编程实践
写在前面
之前写过一篇Go并发编程模式,相对比较片面。最近系统看了下Concurrency in Go, 结合自身的一些实践,形成本文,算是一个读书笔记吧。
为什么需要并发?
摩尔定律逐渐失效,数据规模的不断增长需要充分挖掘多核计算机性能,而并发编程是利器:
Concurrency is the next major revolution in how we write software.
——The Free Lunch Is Over
更多请参考:Herb Sutter 2005年在Dr. Dobb’s 发表的文章:The Free Lunch Is Over。
Go并发编程实践
写在前面
之前写过一篇Go并发编程模式,相对比较片面。最近系统看了下Concurrency in Go, 结合自身的一些实践,形成本文,算是一个读书笔记吧。
为什么需要并发
Concurrency is the next major revolution in how we write software.
—— The Free Lunch Is Over
摘自 Herb Sutter 2005年在Dr. Dobb’s 发表的文章:The Free Lunch Is Over。核心思想是说摩尔定律逐渐失效,但数据规模却在不断增长,我们需要充分挖掘多核计算机性能,而并发编程是编写软件方式的重大革命。
那什么是并发呢?并发跟并行有什么区别?
并发与并行
并发(concurrency)和并行(parallelism)有相关性但却是截然不同的概念。Rob Pike在Concurrency is not parallelism主题演讲中总结的非常好:
Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
—— Concurrency is not parallelism
并发是指同时处理(dealing with)多件事,并行是指同时去做(doing)多件事;并发强调在逻辑上(logically)同时发生;并行强调在物理上(physically)同时发生。
举个例子:单核CPU是可以并发的,但不能并行;多核CPU即可以并发,也可以并行。
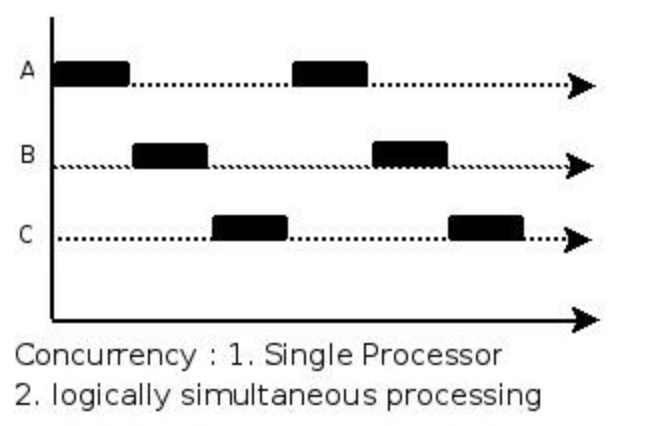

但是,编写正确的并发程序是困难的!
MIT 6.824 Lab1: MapReduce
之前虽然看过很多分布式系统相关的书籍、论文和一些开源项目,但很少自己动手去实现。理论跟工程实现通常有非常大的差别,一个看似很简单的协议,在工程实现上可能非常困难。6.824是MIT开设的分布式系统课程,非常系统的讲解了分布式系统的主流技术,同时将理论和实践相结合,是一个非常好的课程。
本文是笔者在学习6.824 lec1课程的一些总结和思考,算是一个学习笔记。在看这篇文章之前,我希望读者先提前阅读以下资料:
- MapReduce: Simplified Data Processing on Large Clusters
- 6.824 2022 Lecture 1: Introduction and video
- 6.824 Lab 1: MapReduce Guidance
本文主要分三个部分,第一部分概述性的介绍mapreduce的原理;第二部分概述性的介绍mapreduce的实现;第三部分介绍工程实现上需要注意的一些问题,完整代码实现参考github。
使用Go实现批量文件上传
在现在生活中,我们经常在使用文件上传功能,但我们很少会自己去做一个文件上传的服务,了解文件的上传原理有助于我们开发出更健壮的程序。利用Go语言以及其标准库的能力,用很少的代码量就可以实现一个文件上传服务器。本文以小工具的方式讲解如何实现一个简单的文件上传服务器,并假设读者对Go、HTTP、HTML有一定了解。
完整代码参考:github.com/leeyzero/go-tools/uploadserver.go
Server端
文件上传一般使用multipart/form-data上传上传,Go语言标准库其进行了良好的封装,感兴趣的可以直接查询其原码实现。对于文件上传服务器,需要搭建一个简单的服务端框架,幸运的是Go语言http包已经为我们实现了,我们只需要实现一个handler即可,
1 | func uploadHandler(w http.ResponseWriter, r *http.Request) { |
在uploadHandler中,只需要进行以下三个步骤:
1、解析multiform data
2、遍历multiform data中的文件
3、将文件保存至指定位置
OAuth2简明教程
开放授权(OAuth, Open Authorization)是一个开放标准,允许用户让第三方应用访问该用户在某一网站上存储的私密的资源(如照片,视频,联系人列表等),而无需将用户名的密码提供给第三方应用。OAuth2.0是OAuth的2.0版本。本文主要介绍OAuth2的授权流程。
名词解释
- Resource Owner:资源拥有者
- Resource Server:资源服务器
- Client:客户端
- Authorization Server:认证服务器
- User Agent:用户代理,通常指浏览器
场景
在现实生活中就存在OAuth的场景:快递员给你送快递,但他进不了小区,他只能按下你家的门牌号,然后你通过摄像头确认他的确是给你来送快递的快递员,然后你给它解除门禁,快递员就能进入小区了给你送快递了。
在这个例子中,你就是资源拥有者(Resource Owner),小区内基础设施可以理解为资源(Resource),物业就是资源服务器(Resource Server),快递员是客户端(Client),门禁就是认证服务器(Authorization Server)。
你是受认证的业主,可以通过门禁卡、人脸认别等方式自由进入小区。但快递员不是业主,也想进入小区,怎么办呢?你可以直接把门禁卡给他,但这样不安全,所以门禁系统推出一个授权的功能,就是快递员先向你请求要进入小区,经过你的授权后再给他开门。如果你的快递比较多,这个快递员每天都要来送快递,每次都要你给他授权也比较麻烦,然后门禁系统又推出一个带有效期的临时出入卡,比如有效期一个周,那快速员就可以在这一个周之内自由出入小区了。
以上场景就是OAuth授权的原理,为了贴合互联网应用场景,OAuth制定了一套开放标准。
Gin简明教程
Gin是一个用Go语言实现的高性能web框架,其API实现优雅,性能卓越,上手简单,而且比较轻量级,很容易引入到项目中。本文是一篇对Gin框架的学习笔记,不会对Gin框架的用法做面面俱到的,而是对Gin框架做一个整体上的认识与入门。
安装
1、首先需要先安装Go,依赖版本为1.13+,执行下面命令安装Gin:
1 | go get -u github.com/gin-gonic/gin |
2、在代码中引入Gin包
1 | import "github.com/gin-gonic/gin" |
数据密集型应用

最近断断续续花了一个月时间看了一遍数据密集型应用系统设计,也就是大家所说的DDIA(Designing Data-Intensive Applications)。这是一本一看就停不下来的书,强烈安利做业务系统的同学看看。那这本书到底在讲什么呢?
数据模型是对现实世界的抽象,可以从微观角度理解为“数据结构”,它是一个应用系统中最重要的部分。数据模型在一定程度上会影响到系统设计人员解决问题的方式。关系型数据库在很长一段时间大行其道(虽然NoSQL越来越流行,但关系型数据库仍然有一席之地),通常我们在做系统设计时首先会对现实对象建模,建立对象之间的关系,以便能更好的用关系型数据库来表现。然而从这本书中我们可以看到,关系型数据库并不是惟一的数据模型,在做系统设计的时候,不应该受具体数据模型影响,了解各数据模型的优缺点和应用场景,有助于我们设计更具可靠性、可扩展性以及可维护性的系统。
一句话概括:这是一本介绍各种数据库原理及其应用的书。
具体来讲,本书从可靠性、可扩展性和可维护性角度展开,介绍各类数据库原理和应用。全书一共分成了三个部分: