之前排查了一个服务hang死的线上故障,觉得这个问题比较有代表性,本文记录故障排查的经过,并做一些总结和思考。
现象
周末线上一个比较核心的服务(以下称为X服务)出现大量5xx报警。从客户端看到的现象是客户端请求X服务时,出现大量的链接被重置(connection reset by peer)的错误。
分析
从经验来看,90%以上的问题都是上线引入的。故障出现在周末,按规范来说,非特殊情况下,周末是不允许上线,跟相关角色确认后,本次故障不是上线引入。
观察线上流量,在出现故障时间点,流量的确有大幅上涨,从宏观分析来看,有可能流量突然上涨是一个诱因。
任意找了一台有问题的机器,发现了一个比较有意思的现象:服务X出现了大量CLOSE_WAIT状态的连接。从TCP的状态转换可知,CLOSE_WAIT是被动关闭一方在收到FIN并返回ACK后进入的状态。TCP状态机如下:
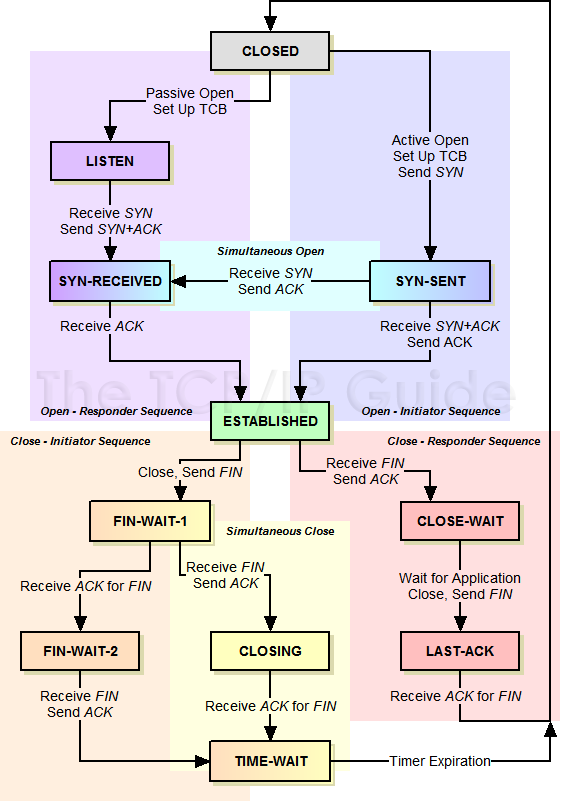
也就是说X服务在收到客户端请求后,客户端关闭连接,还服务端进程并没有关闭连接,分析了web server的框架代码,正常情况下,一个请求处理完后会关闭这个连接,出现这种情况可能是业务逻辑出现阻塞,导致服务端请求的连接一直不能关闭。
查看了一下X服务打开的socket句柄数:
1
2
| $ lsof | grep `ps -ef | grep x-service | grep -v 'grep' | awk '{print $2}'` | grep sock | wc -l
10231
|
发现X服务打开的连接数非常多,达到10231个,看下实例的句柄数上限:
句柄数像是已经被耗尽了,用strace看了下X服务的系统调用:
1
| $ strace -p `ps -ef | grep x-service | grep -v 'grep' | awk '{print $2}'`
|
从系统调用日志中发现了一些关键信息:
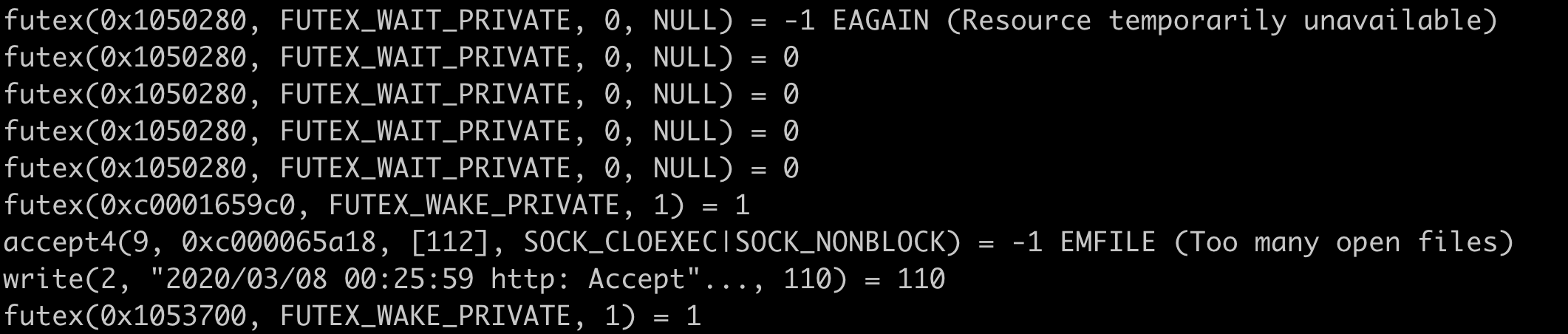
发现大量accept调用报错,从日志信息可以看出,的确是系统的文件句柄数(FD)耗尽了,导致连接被reset掉,这也能说明为什么客户端侧看到了大量connection reset by peer错误了。
X服务打开了大量socket文件句柄,且绝大多数连接状态都是CLOSE_WAIT,如果业务逻辑有阻塞的确可能会出现把句柄数数打满。
分析了一下业务逻辑,业务逻辑本身不复杂,只有一次IO网络请求,是从数据库查询数据,从日志中发现了一些端倪: